Estructuras con Punteros
1. Operador "sizeof" con estructuras
Cuando se aplica el operador sizeof a una estructura, el tamaño obtenido nosiempre coincide con el tamaño de la suma de sus campos.
Por ejemplo:
#include <iostream>
using namespace std;
struct A {int x; char a; int y; char b;};
struct B {int x; int y; char a; char b;};
int main(){
cout << "Tamaño de int: " << sizeof(int) << endl;
cout << "Tamaño de char: " << sizeof(char) << endl;
cout << "Tamaño de estructura A: " << sizeof(A) << endl;
cout << "Tamaño de estructura B: " << sizeof(B) << endl;
cin.get();
return 0;
}El resultado, usando Anjuta , es el siguiente:Tamaño de int: 4Tamaño de char: 1Tamaño de estructura A: 16Tamaño de estructura B: 12Si hacemos las cuentas, en ambos casos el tamaño de la estructura deberíaser el mismo, es decir, 4+4+1+1=10 bytes. Sin embargo en el caso de laestructura A el tamaño es 16 y en el de la estructura B es 12, ¿por qué?La explicación es algo denominado alineación de bytes (byte-aling). Paramejorar el rendimiento del procesador no se accede a todas las posiciones dememoria. En el caso de microprocesadores de 32 bits (4 bytes), es mejor sisólo se accede a posiciones de memoria múltiplos de 4, y el compiladorintenta alinear las variables con esas posiciones.
En el caso de variables "int" es fácil, ya que ocupan 4 bytes, pero con lasvariables "char" no, ya que sólo ocupan 1.Cuando se accede a datos de menos de 4 bytes la alineación no es tanimportante. El rendimiento se ve afectado sobre todo cuando hay que leerdatos de cuatro bytes que no estén alineados.En el caso de la estructura A hemos intercalado campos "int" con "char", demodo que el campo "int" "y", se alinea a la siguiente posición múltiplo de 4,dejando 3 posiciones libres después del campo "a". Lo mismo pasa con elcampo "b"
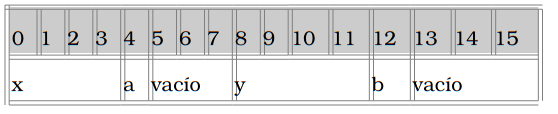
En el caso de la estructura B hemos agrupado los campos de tipo "char" alfnal de la estructura, de modo que se aprovecha mejor el espacio, y sólo sedesperdician los dos bytes sobrantes después de "b".
