IPv4
| Sitio: | Facultad de Ingeniería U.Na.M. |
| Curso: | Redes II - IC421 |
| Libro: | IPv4 |
| Imprimido por: | Invitado |
| Día: | miércoles, 3 de julio de 2024, 06:24 |
Tabla de contenidos
- 1. Comienzo de protocolo IP
- 2. Organigrama Internet
- 3. Introducción.
- 4. RFC791
- 5. Servicios IP
- 6. ¿Como funciona?
- 7. PROTOCOLO IP
- 7.1. Versión
- 7.2. Logitud de Cabecera
- 7.3. Tipo de Servicio.
- 7.4. Longitud Total
- 7.5. Identificador (ID)
- 7.6. Flags o Identificadores.
- 7.7. Desplazamiento u Offset.
- 7.8. Tiempo de Vida.
- 7.9. Protocolo
- 7.10. CRC de Cabecera
- 7.11. Dirección de Origen
- 7.12. Dirección de Destino
- 7.13. Opciones
- 7.14. Relleno
- 7.15. Datos.
- 8. DIRECCIONES IP
- 9. ARP
- 10. Subredes
- 11. Introducción
- 12. Localhost.
- 13. DHCP
- 14. ICMP v.4
- 15. Manual de Ping.
- 16. Comando Traceroute
- 17. Ejemplos uso Traceroute.
- 18. Manual de Traceroute
- 19. Resumen Capa 3
1. Comienzo de protocolo IP
El llamado protocolo TCP/IP, creado por una dupla de científicos en 1974 cambiaron el mundo dando pie a lo que conocemos hoy como internet.
La interconexión de computadores es una idea que se encuentra en desarrollo desde los años 60 con ARPANET, un proyecto del Departamento de Defensa Estadounidense ejecutado por la Agencia de Proyectos de Investigaciones Avanzadas de Defensa (DARPA en inglés) con el propósito de crear una red de computadores que pudiera conectar a diversas instituciones. Los dos primeros nodos de ARPANET se encontraban en la Universidad de California en Los Ángeles, teniendo como responsable a uno de los dos protagonistas de esta historia: Vinton Cerf.
Darpa -> Proyectos ->Arpanet.
Esta agencia del Gobierno Estadounidense tiene muchos proyectos, muchos de ellos parecen ciencia ficción, pero con el tiempo pasan a ser parte de la Realidad.
9 Fabulosos Proyectos de DARPA.
4 Proyectos que te dejarán la boca Abierta.
Por su parte, una empresa llamada Bolt, Beranek & Newman se encontraba trabajando en la arquitectura de hardware de ARPANET, un proyecto que involucraba a quien sería el compañero de Vinton Cerf en la creación del protocolo TCP/IP: Robert Elliot Kahn.
Para octubre de 1972 se celebra La Conferencia Internacional de Comunicaciones Informáticas en donde Kahn lleva a cabo una demostración de su trabajo, conectando 40 computadores, lo que demostró que la transmisión de paquetes de datos en red era una realidad.
 Vint Cerf (Izquierda), Robert Kahn (derecha)
Vint Cerf (Izquierda), Robert Kahn (derecha)
IP (1969)
Primera interconexión entre dos Universidades de California (UCLA) y Stanford , ambas en la costa Oeste de los EEUU en el estado de California.IP (1973)
Vinton Cerf y Robert Kahn venían trabajando en secciones distintas del mismo proyecto, sin embargo, para el año 1973 unen sus conocimientos y plantean la creación de una nueva generación de ARPANET cuyo funcionamiento estaría fundamentado en 4 premisas:
- Interconexión de redes a través de puertas de enlace.
- Descentralización de las redes.
- Recuperación ante errores.
- Compatibilidad universal entre las redes.
En resumen, los 4 principios de su desarrollo buscaban el acceso a cualquier red a través de un dispositivo que sirviera de puerta de enlace, evitar la dependencia a nodos centrales, el reenvío de paquetes que no hayan sido entregados y la conexión entre redes sin realizar cambios internos.
Para hacerlo realidad Cerf y Kahn se influenciaron en el trabajo previo de ARPANET, sin embargo, hubo una investigación clave, de origen francés que resultó determinante para este desarrollo: CYCLADES. Se trataba de una investigación liderada por Louis Pouzin como una alternativa al proyecto ARPANET y cuyo aporte trascendental fue poner la entrega de los datos en manos del host, en lugar de la red.
1974-TCP
Es en el año 1974 cuando Cerf y Kahn presentan lo que llamaban Programa de Control de Transmisión, una serie de instrucciones con la función de transmitir y enrutar los datos a través de una red de computadores. Sin embargo, el cumplimiento de estas dos funciones podría complicarse a medida que aumentaba el crecimiento y exigencia de la red, poniendo en riesgo dos factores importantísimos en la tecnología: la escalabilidad y flexibilidad.
El 30 de agosto de 1974 con el nombre de Facultad de Ingeniería Electromecánica en Oberá Misiones.
En este punto el programa TCP comenzó a ser conocido mundialmente y esto trajo consigo las opiniones de muchos expertos en el área. Uno de ellos fue Jonathan Postel del Instituto de Ciencias de La Información de la Universidad de California, quien notando esto sugirió la división del programa en capas, lo que posteriormente dio pie al surgimiento del TCP/IP.
Con la creación del protocolo TCP/IP la Agencia de Proyectos de Investigaciones Avanzadas de Defensa (DARPA) recurrió a la empresa Bolt, Beranek & Newman, la Universidad de Stanford y el University College de Londres, a fin de crear nuevas versiones del protocolo TCP/IP basados en diferentes plataformas de hardware.
De esta manera, comenzaron a surgir las distintas versiones del protocolo que empezaron a probarse en 1975 con la conexión de los nodos entre las universidades de Stanford y Londres. Posteriormente, para el año 1977 se estableció la comunicación de 3 nodos, sumando a Noruega junto al Reino Unido y Estados Unidos.
1980-1983
A inicio de la década de los 80, TCP/IP se presentaba en su versión 4 con un funcionamiento impecable en la entrega y transmisión de datos. Así, para el año 1983 el Departamento de Defensa Estadounidense decreta al protocolo TCP/IP como el estándar de todas las redes militares.
1985
Con todos estos avances, en el año 1985, la Internet Architecture Board o Junta de Arquitectura de Internet lleva a cabo una conferencia de 3 días, acerca del uso comercial del protocolo TCP/IP. En ese sentido, hablamos de las primeras intenciones de llevar a nuestros hogares la posibilidad de conexión a la red mundial.
1986
La NSF Fundación Nacional de Ciencias comienza el desarrollo de NSFNET, que se convirtió en la principal Red en árbol de Internet, complementada después con las redes NSINET y ESNET, todas ellas en Estados Unidos.
Paralelamente, otras redes troncales en Europa, tanto públicas como comerciales, junto con las americanas formaban el esqueleto básico ("backbone") de Internet
1989 -WWW, HTML
Con la integración de los protocolos OSI en la arquitectura de Internet, se inicia la tendencia actual de permitir no solo la interconexión de redes de estructuras dispares, sino también la de facilitar el uso de distintos protocolos de comunicaciones.29 Entre finales de 1989 y principios de 1990, en el CERN (Organización Europea para la Investigación Nuclear) de Ginebra, un grupo de físicos encabezado por Tim Berners-Lee crea el lenguaje HTML basado en el SGML, y además el servicio hoy más popular de Internet: la World Wide Web (WWW).
1993
Mosaic , primer navegador Web.
2006.
Internet alcanza los mil cien millones de usuarios.
Actualidad.
Hoy en día el protocolo TCP/IP en su versión 4 es la base fundamental para la existencia del internet tal y como lo conocemos. Sin embargo, los desarrollos en este ámbito no paran y al vislumbrarse el agotamiento de las direcciones IPv4, comenzó el desarrollo de la versión 6 del protocolo que en estos momentos se ha implementado en muchos países del mundo y aunque las mejoras que presenta son sustanciales, se trata de un mecanismo que continúa trabajando sobre las ideas planteadas hace mas de 45 años por Cerf y Kahn.
Material Obtenido de https://www.tekcrispy.com
2. Organigrama Internet
De manera muy simplificada pretendemos presentar a modo informativo como podríamos presentar la estructura de como se organiza Internet.
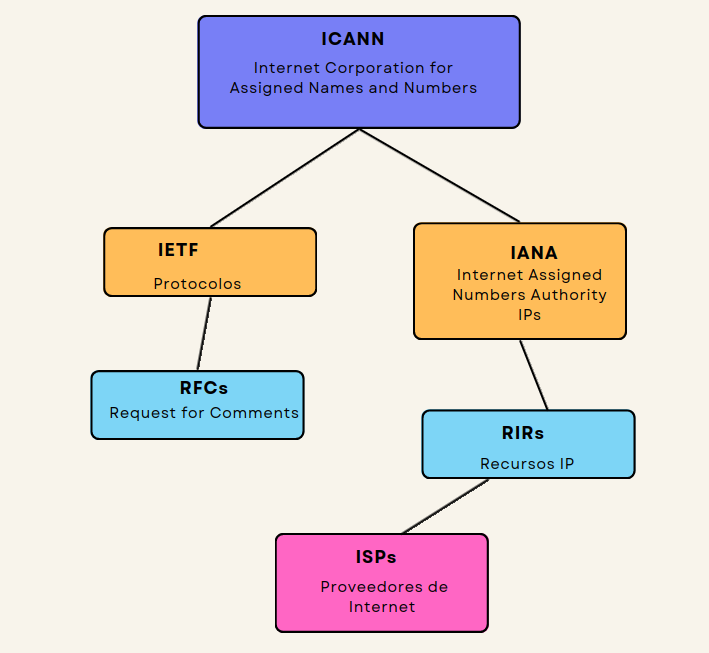
ICANN (Internet Corporation for Assigned Names and Numbers)
ICANN administra la coordinación general y el desarrollo de políticas para nombres de dominio, direcciones IP y parámetros de protocolo. También supervisa la función de la IANA.
IANA (Internet Assigned Numbers Authority)
IANA (parte de ICANN) administra la asignación real de direcciones IP,
nombres de dominio y parámetros de protocolo de acuerdo con los
estándares desarrollados por IETF y las políticas establecidas por
ICANN.
IETF (Internet Engineering Task Force)
IETF desarrolla y estandariza los protocolos y estándares técnicos que definen cómo funciona Internet.
RIRs (Registros regionales de Internet)
los RIR son organizaciones que administran la asignación y el registro de direcciones IP y números de sistemas autónomos dentro de regiones específicas. Hay cinco RIR a nivel mundial, cada uno responsable de un área geográfica diferente: ARIN (América del Norte), RIPE NCC (Europa, Medio Oriente, Asia Central), APNIC (Asia-Pacífico), LACNIC (América Latina y el Caribe) y AFRINIC ( África).
RFCs ( Request for Comments)
El Request for Comments (RFC) es un documento numérico en el que se describen y definen protocolos, conceptos, métodos y programas de Internet.
2.1. ICANN (Informativo)
Internet Corporation for Assigned Names and Numbers ICANN
Todos
los días usamos, indirectamente, sus servicios, pero es probable que no
sepamos que ICANN es la entidad que administra los recursos principales
de identificación e ingeniería de Internet.
La
Corporación Internet para Nombres y Números Asignados, ICANN, por sus
siglas en inglés, es una entidad privada, sin fines de lucro, para
beneficio público, compuesta de grupos y personas de diferentes partes
del mundo.
Su principal tarea y misión es mantener Internet en una forma
segura, estable e interoperable. Promueve la competencia y desarrolla
políticas acerca de los identificadores únicos en Internet.
ICANN
no controla el contenido en Internet. No puede detener el correo basura
y no tiene que ver con el acceso a Internet. ICANN coordina y trabaja
en conjunto con todos los operadores del sistema de nombres de dominio,
de direcciones IP y de números de protocolo que hay en el mundo.
A
cargo de ICANN y sus asociados se encuentra la operación segura,
estable e interoperable de los servidores raíz en el mundo. Los
servidores raíz (root servers) son los computadores que, diseminados por
todo el mundo, mantienen una copia actualizada del nivel básico de
conversiones entre nombres y direcciones. A partir de estos servidores
raíz, es posible, por medio de una serie de preguntas recursivas,
encontrar cualquier dirección válida en Internet.
Visto
de otra forma, cada vez que enviamos un mensaje de correo electrónico, o
revisamos un sitio web, independientemente de dónde se halle el
destinatario o el servidor del sitio, estamos haciendo uso de una serie
de números, estándares, nombres y protocolos cuya definición,
mantenimiento y mejora está en el ámbito de acción de ICANN.
La organización de ICANN
ICANN
es una organización que toma muy en serio ser una institución abierta y
que escucha opiniones, contrarias y favorables, de la manera más
democrática posible. Sostiene 3 reuniones presenciales en el año, y en
ellas puede participar cualquier empresa o persona. También es posible
ser miembro de una de las varias organizaciones que componen ICANN, y de
esta manera, incluso, llegar a ser parte de la Junta de Directores de
ICANN.
La organización de ICANN aparece en la siguiente figura:
Organigrama de ICANN
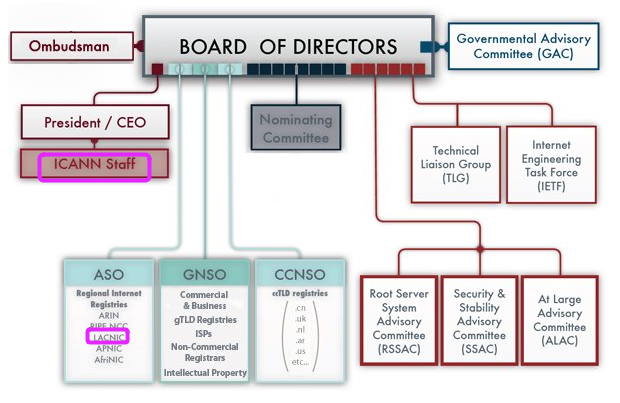
La
Junta de Directores, con 21 miembros, es la autoridad máxima. Los
distintos miembros son nombrados por períodos de 3 años, renovables, y
son designados por alguna de las organizaciones de soporte o comités
asesores de ICANN.
Las
3 organizaciones de soporte representan los 3 recursos que son
administrados por la comunidad Internet en el mundo. Se trata de la ASO
(Organización de Soporte de Direcciones), la GNSO (Organización de
Soporte de Nombres de Dominio Genéricos) y la CCNSO (Organización de
Soporte de Nombres de Dominio de Código de País). Cada una de estas
organizaciones nombra a 2 miembros de la Junta de Directores.
Además de las organizaciones de soporte, se encuentran 4 Comités Asesores: El Comité Asesor sobre el Sistema de Servidores Raíz (RSSAC), el Comité Asesor sobre Seguridad y Estabilidad (SSAC), el Comité Asesor Ampliado (ALAC) y el Comité Asesor Gubernamental (GAC). Los 3 primeros nombran a 4 miembros de la Junta de Directores. El representante del GAC no tiene voto en la Junta de Directores. Esta es una forma de hacer evidente que, aunque hay una relación formal con los gobiernos del mundo, ésta no es vinculante.
Por otro lado, el Comité Asesor Ampliado (ALAC) es probablemente la estructura más abierta de ICANN, pues cualquier organización con interés en Internet, en el mundo, puede afiliarse a este comi+e, y participar en el mismo.
Hay otros dos grupos con objetivos concretos, y que nombran a 2 miembros de la Junta de Directores: el Grupo de Vinculación Técnica (TLG) y la Fuerza de Tarea de Ingeniería Internet (IETF). Estos grupos tienen responsabilidades en las áreas más técnicas de Internet.
Finalmente, está el Comité de Nominaciones (NOMCOM), cuya tarea es buscar, entrevistar y seleccionar a 8 miembros de la Junta de Directores. Para ello, busca balancear las nominaciones y candidaturas utilizando criterios de distribución geográfica y de género, de forma que además de las condiciones mínimas de idoneidad para el cargo, también se mantenga esta disparidad en la Junta de Directores.
Los 3 temas más relevantes que se plantean en la actualidad en los foros de ICANN son:
Nuevos gTLDs
Hasta
la fecha, los siguientes 16 gTLD (Nombres de Dominios Genéricos)
existen en Internet y sus administradores mantienen contrato con ICANN.
En orden alfabético y anteponiendo un punto antes de cada nombre: AERO,
ASIA, BIZ, CAT, COM, COOP, INFO, JOBS, MOBI, MUSEUM, NAME, NET, ORG,
PRO, TEL, TRAVEL.
En marzo de este año se publicó la versión 2 de
la “Guía para el Aplicante a nuevos Nombres de Dominio Genéricos”. Se
han recibido comentarios y se están discutiendo, sobre todo en los temas
de protección de marcas registradas, comportamiento malicioso,
seguridad y estabilidad, y análisis económico. Se espera contar con la
versión 3 de la Guía a fines de este año 2009, y proceder a su
implementación a partir de marzo de 2010.
IDN
Nombres
de Dominio Internacionalizados, significa el uso de caracteres que
hasta hoy solamente aparecen en alguna parte de la dirección de un sitio
web, por ejemplo, o en el interior de un portal determinado.
Se
trata de caracteres que no forman parte del alfabeto de origen latino
que usamos, por ejemplo, en castellano o inglés. Los millones de
internautas de origen chino, ruso, árabe, japonés, koreano, persa,
indio, etc. no pueden escribir las direcciones en Internet usando
solamente los caracteres de sus respectivos idiomas. En el mejor de los
casos, pueden escribir la mayor parte de un sitio web en caracteres
chinos, pero deben terminarlo en “.CN”, por ejemplo, que es el código
del país China, pero escrito en nuestro caracteres, no en los de ellos.
Por
supuesto, hay una presión muy fuerte para que Internet pueda leer y
comprender esos caracteres de esas muchas lenguas que usan formas
escritas diferentes a las nuestras. El incremento del uso de Internet
cuando esto sea logrado será impresionante, ya que permitirá a los
nativos de todas esas lenguas que, sin aprender ni un solo carácter
ajeno a su cultura, puedan navegar en Internet, en su propio idioma.
Para
nuestra lengua, el español, los IDN significan la lectura apropiada de
caracteres como las vocales tildadas y la letra “ñ”. Hasta ahora hemos
podido vivir así, y aunque será bueno que podamos escribir con buena
ortografía los nombres de dominio, no es algo que realmente frene la
expansión de Internet en nuestros países.
Mejorar la confianza institucional
Este
otro tema es más de corte político, y está relacionado con el hecho de
que a finales de septiembre de 2009, concluye, una vez más, el acuerdo
que ICANN ha firmado con el Departamento de Comercio de los Estados
Unidos, y cuya renovación, cambio o conclusión está discutiendo el
congreso norteamericano en estos días.
El sueño de cortar
definitivamente el cordón umbilical de ICANN con el gobierno de los
Estados Unidos (recordemos que en este país se originó Internet) pasa
por dar pruebas, como cualquier adolescente, de madurez, confianza en sí
mismo, y proyección de autonomía. ICANN fue fundado en 1998, pero ha
demostrado en estos once años que puede administrarse a sí mismo, y a la
gran responsabilidad de mantener una Internet segura, estable e
interoperable. Veremos si el congreso estadounidense piensa lo mismo.
2.2. IANA-RIRs
IANA: https://www.iana.org/
La entidad Internet Assigned Numbers Authority desempeña un papel esencial en la gestión de Internet, ya que es responsable de asignar nombres y sistemas de números únicos que se usan de acuerdo con los estándares técnicos –protocolo de red– de Internet y constituyen la base del direccionamiento de páginas web. Aunque Internet no es una red gestionada de forma centralizada, debido a determinadas circunstancias técnicas algunos componentes básicos deben coordinarse a escala mundial, actividad de la que ya se ocupaba la IANA con ARPANET, lo que la convierte en una de las instituciones más antiguas de Internet.
Desde 1998, la IANA se constituye como una sección de la ICANN, organización compuesta, además, por otros grupos que representan diferentes intereses en Internet y participan juntos en la toma de decisiones. Se dividen en organizaciones de apoyo (supporting organisations) y comités asesores (advisory commitees).

RIRs.
- 1. AfriNIC (African Network Information Centre), región África http://www.afrinic.net
2. APNIC (Asia Pacific Network Information Centre), región Asia/Pacífico http://www.apnic.net - 3. ARIN (American Registry for Internet Numbers), región América del Norte http://www.arin.net
- 4. LACNIC (Regional Latin-American and Caribbean IP Address Registry), América Latina y algunas islas del Caribe http://www.lacnic.net (LANIC Link)
- 5. RIPE NCC (Reseaux IP Europeans), Europa, Medio Oriente y Asia Central http://www.ripe.net
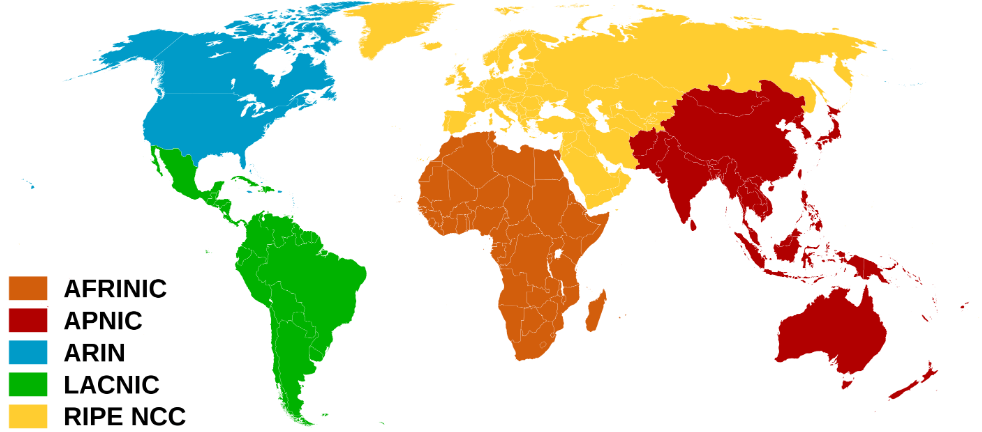
Cada nivel inferior obtiene conectividad al backbone por medio de la conexión a un ISP de nivel superior. La Gerarquía o nivel se conoce como Tier ( nivel ) y los hay Tier1, Tier2 y Tier3.
Desde los Tier1 hacia Tier3 se van distribuyendo las IPs.
Observación: Tier en ingles significa nivel
3. Introducción.
EL PROTOCOLO INTERNET
En esta sección se examina la versión 4 de IP, definida oficialmente en el RFC 791. Aunque la intención es que IPv6 reemplace a IPv4, éste es actualmente el estándar IP utilizado en las redesTCP/IP. El protocolo Internet (IP Internet Protocol) es parte del conjunto de protocolos TCP/IP y es el protocolo de inter-conexión de redes más utilizado.
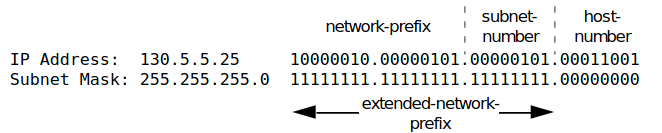
Como con cualquier protocolo estándar, IP se especifica en dos partes: La interfaz con la capa superior (por ejemplo, TCP), especificando los servicios que proporciona IP. El formato real del protocolo y los mecanismos asociados.
En esta sección se examinan primero los servicios de IP y después el protocolo IP. A esto seguirá una discusión del formato de las direcciones IP. Finalmente, se describe el protocolo de mensajes de control de Internet (ICMP, Internet Control Message Protocol - Protocolo de Mensajes de Control de Internet ), que es una parte integral de IP.
Vista de Pila de protocolos TCP/IP
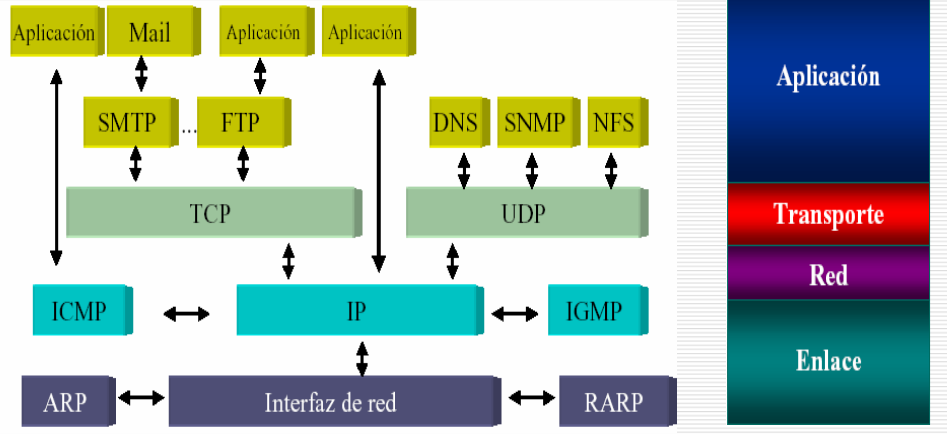
4. RFC791
En el siguiente enlace: RFC 791 (PDF), se puede visualizar el Request For Coment 791, un documento de Darpa con las especificaciones del protocolo IP.
En particular este RFC es de 1981.
Existe un sitio web, de donde se pueden ver todos los RFC, en particular aqui podemos acceder al de RFC791.
Se desarrollaron así cuatro versiones diferentes: TCP v1, TCP v2, una tercera dividida en dos TCP v3 y IP v3 en la primavera de 1978, y después se estabilizó la versión TCP/IP v4 — el protocolo estándar que todavía se emplea en Internet.
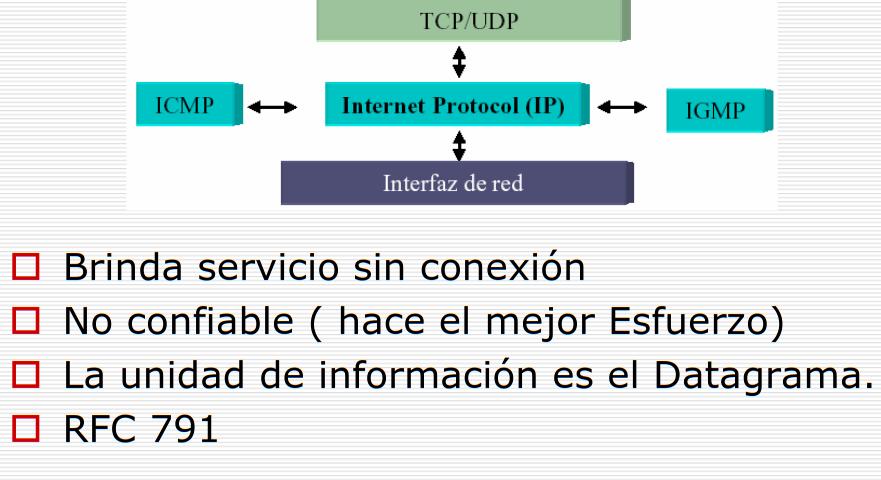
5. Servicios IP
A continuación se presentan los Servicios que Brinda IP:
- Brinda servicio sin conexión.
- No confiable ( hace el mejor Esfuerzo ).
- La unidad de información es el Datagrama.
Responsabilidades de IP
- Usar un esquemas de direcciones para rutear los datagramas hasta al destino.
- Usar un protocolo complementario para reportar problemas (ICMP).
- Fragmentar y reensamblar paquetes para adaptarlos al enlace.
- Rutear paquetes desde el origen al destino.
- Dirección origen: dirección global de red de la entidad IP que envía la unidad de datos.
- Dirección destino: dirección global de red de la entidad IP de destino.
- Protocolo: entidad de protocolo receptor (un usuario IP, como por ejemplo TCP))
- Indicadores del tipo de servicio: utilizado para especificar el tratamiento de la unidad de datos en su transmisión a través de los componentes de las redes.
- Identificador: utilizado en combinación con las direcciones origen y destino y el protocolo usuario para identificar de una forma única a la unidad de datos. Este parámetro se necesita para reensamblar e informar de errores.
- Indicador de no fragmentación: indica si IP puede fragmentar los datos para realizar el transporte.
- Tiempo de vida: medido en segundos.
- Longitud de los datos: longitud de los datos que se transmiten.
- Datos de opción: opciones solicitadas por el usuario IP.
- Datos: datos de usuario que se van a transmitir.
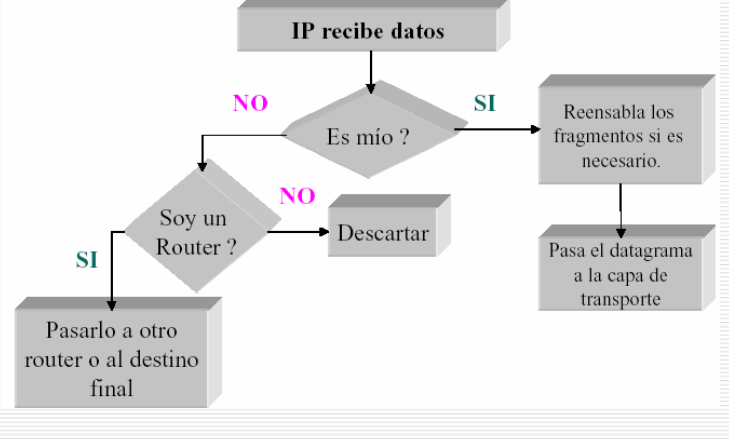
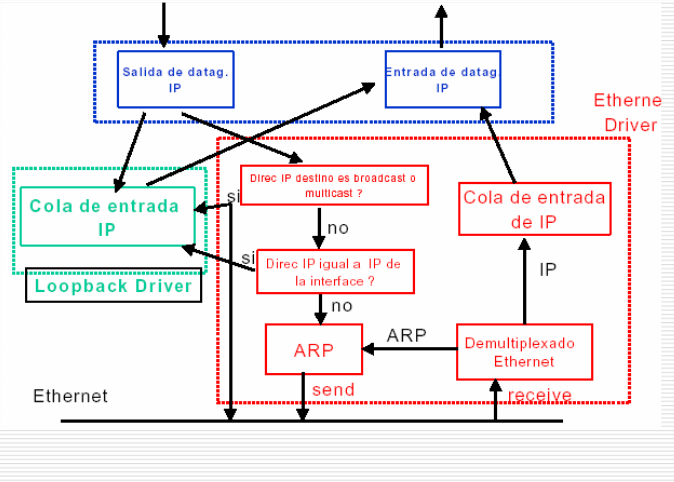
6. ¿Como funciona?
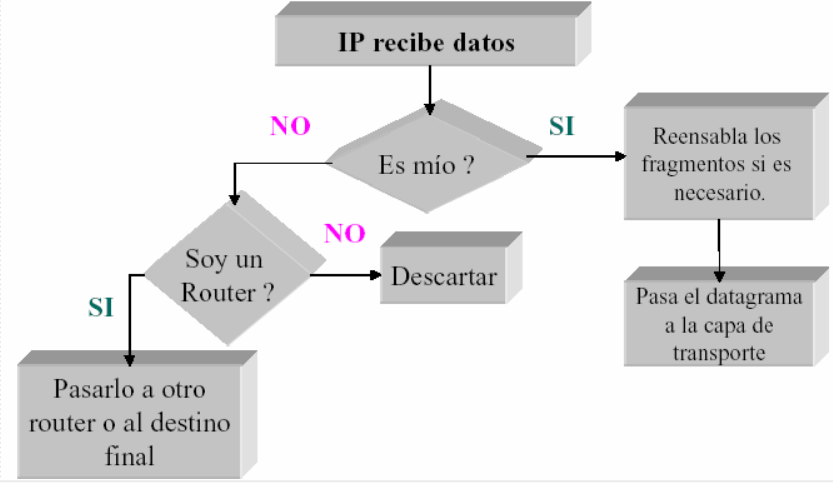
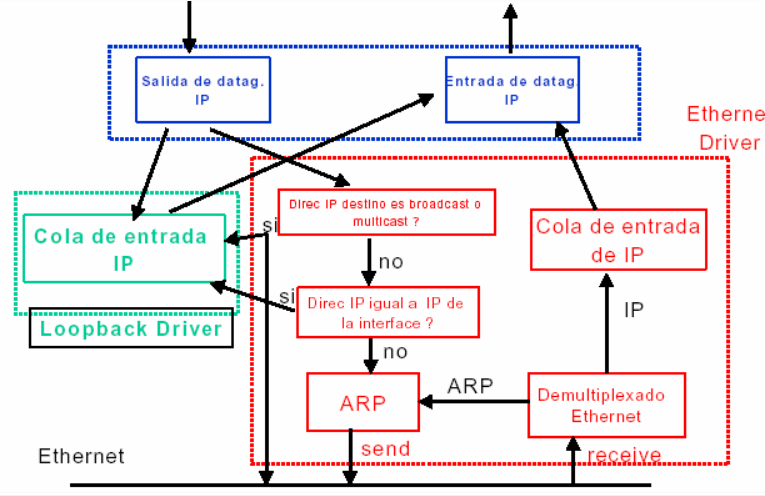
Notar:
- Loopback.
- Driver.
7. PROTOCOLO IP
El protocolo entre entidades IP se describe mejor mediante la referencia al formato del datagramaIP mostrado en la Figura 18.6.
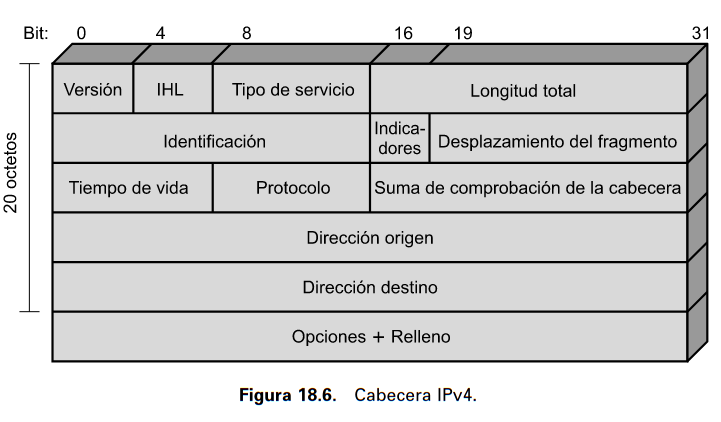 Figura 1
Figura 1
El header o encabezado de un Datagrama, así se conoce a la (UDP) Unidad de Datos de Protocolo IP, tiene 20 bytes u octetos.
7.1. Versión
Versión (4 bits):
Indica el número de la versión del protocolo, permite la interpretación de los campos subsiguientes; el valor es 4 acorde a IPv4.
7.2. Logitud de Cabecera
Longitud de la cabecera Internet (IHL, Internet Header Length) (4 bits):
Longitud de la cabecera expresada en palabras de 32 bits.
El valor mínimo es de cinco, correspondiente a una longitud de la cabecera mínima de 20 octetos.
7.3. Tipo de Servicio.
Tipo de servicio (8 bits):
Especifica los parámetros de fiabilidad, prioridad, retardo y rendimiento.
Este campo NO se utiliza en Internet, no se implementó el uso de manera global, solo se podría implementar en un entorno privado o local, pero no global. Los primeros 6 bits del campo son denominados ahora campo de servicios diferenciados(DS, Differentiated Services). Los 2 bits restantes están reservados para un campo de notificación explícita de congestión (ECN Explicit Congestion Notification), actualmente en fase de estandarización. El campo ECN proporciona una señalización explícita de congestión de una manera similar a la discutida para retransmisión de tramas.
7.4. Longitud Total
Longitud total (16 bits):
Longitud
total del datagrama, en octetos, es importante notar la palabra
octetos, ya que existe otro campo que indica la cantidad pero en
longitudes de 32 bits.
Con este campo y el campo de Longitud de Header, restando ambos podemos determinar la cantidad de bytes de datos, que es un número variable.
7.5. Identificador (ID)
Identificador (16 bits):
Un número de secuencia que, junto a la dirección origen y destino y el protocolo usuario, se utiliza para identificar de forma única un datagrama. Por tanto, el identificador debe ser único para la dirección origen del datagrama, la dirección destino y el protocolo usuario durante el tiempo en el que el datagrama permanece en la red.
 Actividad / Preguntas para el Alumno:
Actividad / Preguntas para el Alumno:
- ¿Cuántos IDs distintos puedo tener?
- Suponiendo que envío 4G de datos, con datagramas de 1500 bytes ¿Existiría algún problema?.
- ¿Qué pasa si se envían los 4G en 30 segundos?.
- ¿Qué pasa si se envían los 4G en 2 minutos?
7.6. Flags o Identificadores.
Indicadores (3 bits):
Solamente dos de estos tres bits están actualmente definidos.
El primer bit está reservado y vale siempre cero.
El bit de «más datos» se utiliza para la fragmentación y el reensamblado, se verá mas adelante este mecanismo.
El bit de «no fragmentación» prohíbe la fragmentación cuando es 1. Este bit puede ser útil si se conoce que el destino no tiene capacidad de reensamblar fragmentos. Sin embargo, si este bit vale 1, el datagrama se descartará si se excede el tamaño máximo de una reden la ruta. Por tanto, cuando el bit vale 1, es aconsejable utilizar encaminamiento desde el origen para evitar redes con tamaño de paquete máximos pequeños.

7.7. Desplazamiento u Offset.
Desplazamiento del fragmento (13 bits):
Indica el lugar donde se sitúa el fragmento dentro del datagrama original, medido en unidades de 64 bits. Esto implica que todos los fragmentos excepto el último, contienen un campo de datos con una longitud múltiplo de 64 bits.
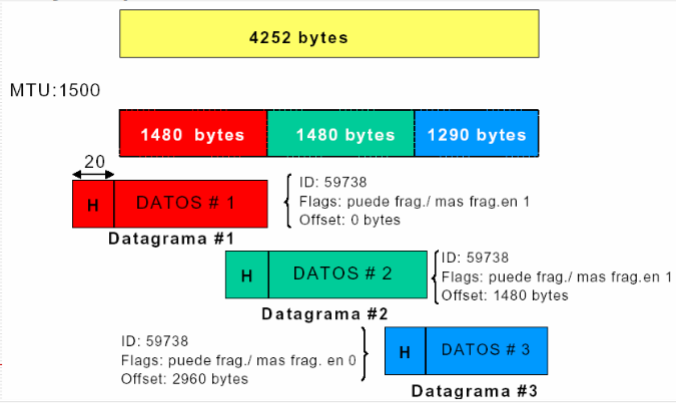
7.8. Tiempo de Vida.
Tiempo de vida (8 bits):
Especifica cuánto tiempo, en segundos, se le permite a un datagrama permanecer en la red.
Cada dispositivo de encaminamiento que procesa el datagrama, debe decrementar este campo al menos en una unidad, de forma que el tiempo de vida es de alguna forma es similar a una cuenta de saltos, en IPv6 se llama "HOP LIMIT".
Conclusión: el valor de TTL será un valor que tenga en consideración la cantidad máxima de saltos o routers por los que podrá pasar el paquete desde el origen hasta el destino.
NOTA: En esta sección hablamos de tiempo de vida, pero en realidad se reduce a contar saltos de routers, no tiempo, finalmente esto es "contador".
TTL de un ping a un DNS.
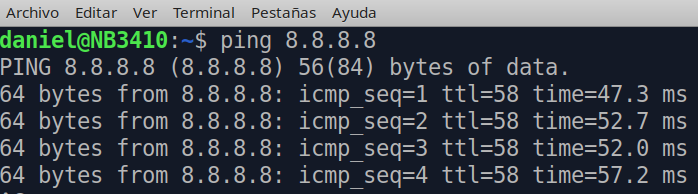 Figura 3
Figura 3
En este caso vemos que el TTL es de 58 en el ping a un DNS (1.1.1.1). Si intentamos ver algo de información mas detallada de la traza de ruta (traceroute) .
 Figura 4
Figura 4
Vemos que dice 30 hops max.
Con esto vemos que dista mucho de los 255 que permite el campo. Un valor inicial que se recomienda es 64.
El campo TTL lo establece el remitente del datagrama y lo reduce cada router (capa 3) en la ruta a su destino. Si el campo TTL llega a cero antes de que el datagrama llegue a su destino, el datagrama se descarta y se envía un datagrama de error del ICMP (RFC792) (Tiempo excedido ) al remitente (que vemos mas adelante en la materia). El propósito del campo TTL es evitar una situación en la que un datagrama que no se puede entregar sigue circulando en un sistema de Internet, y tal sistema eventualmente se ve inundado por tales "inmortales".
 Figura 6
Figura 6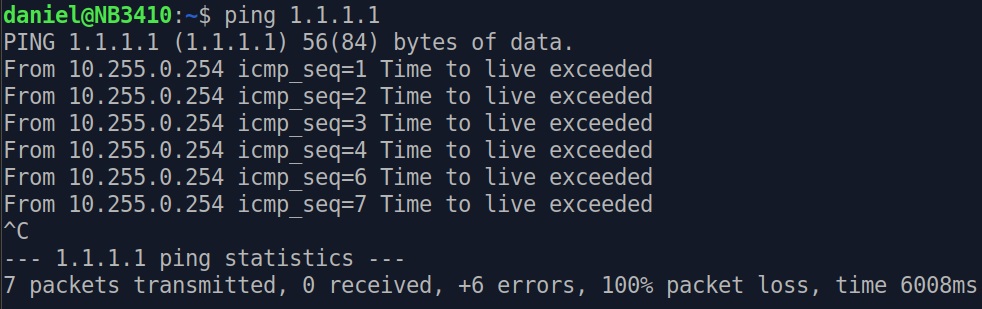 Figura 7
Figura 7
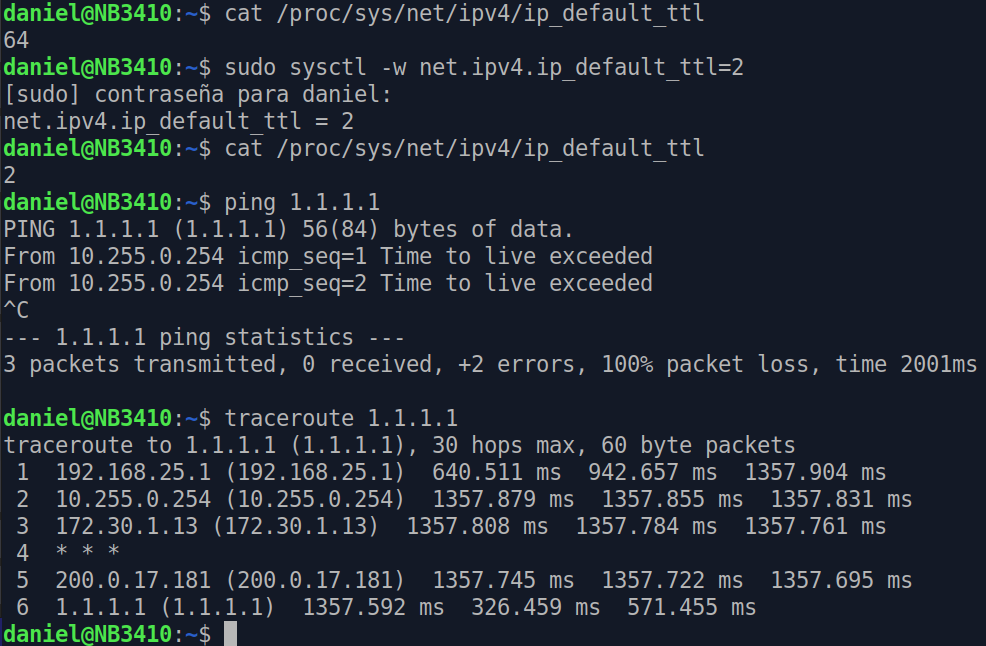 Figura 8
Figura 8
7.9. Protocolo
Protocolo (8 bits):
Identifica el protocolo de la capa de red inmediatamente superior que va a recibir el campo de datos en el destino; así, este campo sirve para identificar el siguiente tipo de cabecera presente en el paquete después de la misma.
7.10. CRC de Cabecera
IP.Suma de comprobación de la cabecera (16 bits):
Un código de detección de errores aplicado solamente a la cabecera. Ya que algunos campos de la cabecera pueden cambiar durante el viaje (por ejemplo, el tiempo de vida y los campos relacionados con la segmentación), este valor se verifica y recalcula en cada dispositivo de encaminamiento.
El campo suma de comprobación es el complemento a uno de la suma de todas las palabras de 16 bits en la cabecera. Para el cálculo, este campo se inicializa a sí mismo a un valor de todo cero.
Luego de calculado el CRC sobre todo el Header ( con ceros en el campo de CRC) , se reemplaza el valor obtenido en el header.
7.11. Dirección de Origen
Dirección de origen (32 bits):
Codificada para permitir una asignación variable de bits para especificar la red y el sistema final conectado a la red especificada, como se discute posteriormente.
7.12. Dirección de Destino
Dirección destino (32 bits):
Igual que el campo anterior describe la dirección de capa 3 (IP ) del host de destino.
7.13. Opciones
Opciones (variable):
Contiene las opciones solicitadas por el usuario que envía los datos (este campo rara vez se utiliza).
7.14. Relleno
Relleno (variable):
Se usa para asegurar que la cabecera del datagrama tiene una longitud múltiplo de 32 bits.
7.15. Datos.
Datos (variable):
El campo de datos debe tener una longitud múltiplo de 8 bits.
La máxima longitud de un datagrama (campo de datos más cabecera) es de 65.535 octetos.
8. DIRECCIONES IP
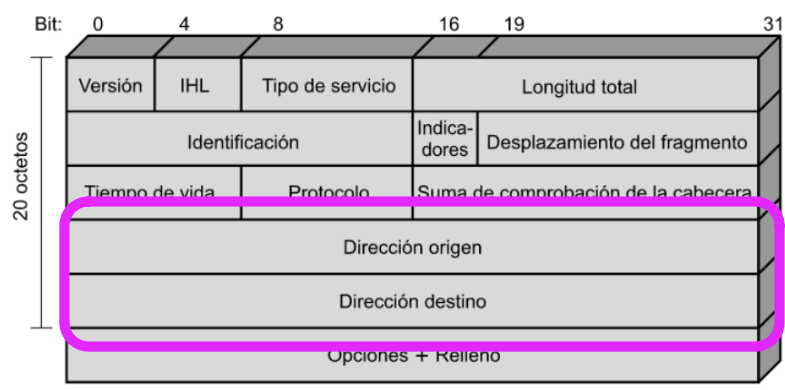 Figura 1
Figura 1
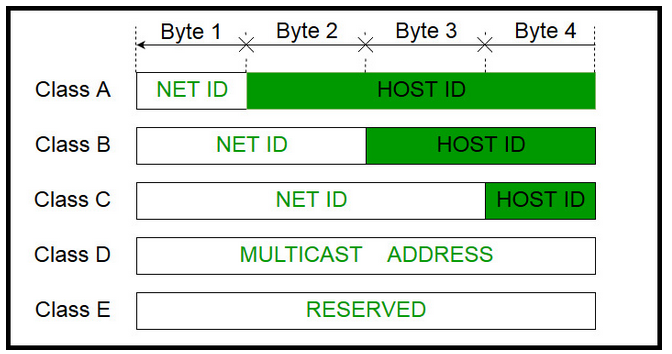
Los campos dirección origen y destino en la cabecera IP contienen cada uno una dirección de internet global de 32 bits que, generalmente, consta de un identificador de red y un identificador de computador.
Clases de red
La dirección está codificada para permitir una asignación variable de bits con la finalidad de especificar la red y el computador, como se muestra en la Figura. Este esquema de codificación, proporciona flexibilidad al asignar las direcciones a los computadores y permite una mezcla de tamaños de red en un conjunto de redes. Este esquema de direcciones se conoce como Classful.
Existen tres clases principales de redes que se pueden asociar a las siguientes condiciones:
-
Clase A: pocas redes, cada una con muchos computadores.
-
Clase B: un número medio de redes, cada una con un número medio de computadores.
-
Clase C: muchas redes, cada una con pocos computadores.
Las clases D y E están reservadas para fines experimentales y de multidifusión, respectivamente.
En un entorno particular, podría ser mejor utilizar todas las direcciones de una misma clase.
Por ejemplo, en un conjunto de redes de una entidad, consistente en un gran número de redes de área local departamentales, podría ser necesario usar direcciones de clase C exclusivamente.
Sin embargo, el formato de las direcciones es tal que es posible mezclar las tres clases de direcciones en el mismo conjunto de redes; esto es lo que se hace en el caso de la misma Internet.
En el caso de un conjunto de redes formado por pocas redes grandes, muchas redes pequeñas y algunas redesde tamaño mediano, es apropiado utilizar una mezcla de clases de direcciones.
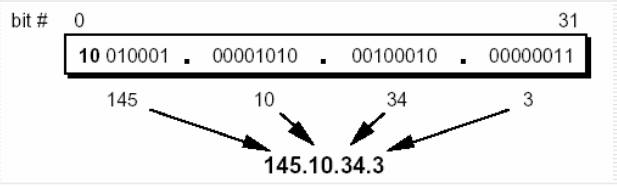
Las direcciones IP se escriben normalmente en lo que se llama notación punto decimal, utilizando un número decimal para representar cada uno de los octetos de la dirección de 32 bits.
Por ejemplo, la dirección IP 11000000 11100100 00010001 00111001 se escribe como 192.228.17.57.
- Las direcciones de red de clase A empiezan
- clase A empiezan con un 0 binario. Las direcciones de red con el primer octeto puesto a 0 (en binario 00000000) o que sea 127 (en binario01111111) están reservadas. Por tanto, existen 126 números de red potenciales de clase A en los cuales su primer octeto en formato punto decimal está en el rango de 1 a 126.(2 8-1 = 128 redes, 2 24= 16777216 hosts)
- Las direcciones de red de clase B comienzan con un número binario 10, de forma que su primer número decimal está entre 128 y 191 (en binario entre 10000000 y 10111111). El segundo octeto también forma parte de la dirección de clase B, de forma que existen 16.384 direcciones de clase B. (216-2 = 16384, redes , 2 16 =65536 hosts )
- Las direcciones de clase C, el primer número decimal va de 192 a 223 (de 11000000 a 11011111). El número total de direcciones de clase C es de 2.097.152. (224-3 = 2097152 , 2 8 =256 hosts)

Como regla práctica podemos ver que la ubicación del 1er bit cero determina el tipo de red ( A,B,C).
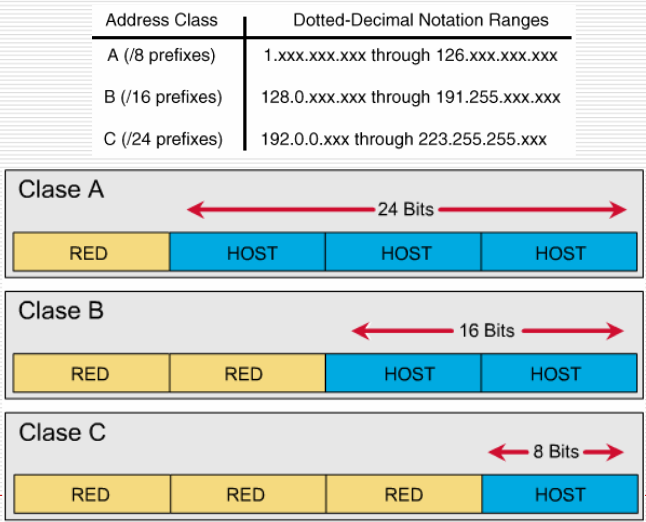
La forma de expresar la dirección IP se conoce como: Notación decimal con Punto.
Redes Privadas.


- Notar que la IP privada clase B NO es /16!! si no /12.
- Notar que la IP privada clase C NO es /24!! si no /16
8.1. Pros y Contras de Direcciones Privadas
Ventajas y desventajas de usar el espacio privado de direcciones.
La ventaja obvia de usar un espacio de direcciones privado para Internet
en general es conservar el espacio de direcciones globalmente único al no
usarlo donde no se requiere unicidad global.
Las propias empresas, casa también disfrutan de una serie de beneficios de su
uso del espacio privado de direcciones: ganan mucha flexibilidad en
diseño de red al tener más espacio de direcciones a su disposición que
podrían obtener del grupo globalmente único.
Esto permite
esquemas de direccionamiento operacional y administrativamente convenientes como
así como caminos de crecimiento más fáciles.
Por una variedad de razones, Internet ya ha encontrado
situaciones en las que una empresa que no se ha conectado a la
Internet había utilizado el espacio de direcciones IP para sus hosts sin obtener este
espacio asignado por la IANA.
En algunos casos, este espacio de direcciones tenía
ya ha sido asignado a otras empresas. Si tal empresa
se conectaría más tarde a Internet, esto podría crear potencialmente
problemas muy serios, ya que el enrutamiento IP no puede proporcionar
operaciones en presencia de direccionamiento ambiguo.
Aunque en principio Los proveedores de servicios de Internet deben protegerse contra tales errores a través de el uso de filtros de ruta, esto no siempre sucede en la práctica. El uso de un espacio de direcciones privado proporciona una opción segura para tales empresas, evitando choques una vez que se necesita conectividad externa.
Un gran inconveniente del uso del espacio privado de direcciones es que puede
en realidad reducen la flexibilidad de una empresa para acceder a Internet.
DHCP. Mapeo de puertos. NAT. PAT. Port Forwarding, etc.
Una analogía que permite visualizar este escenario sería.
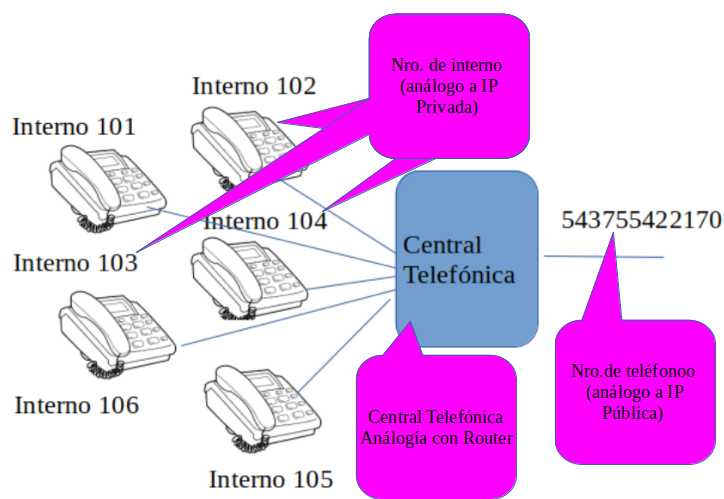
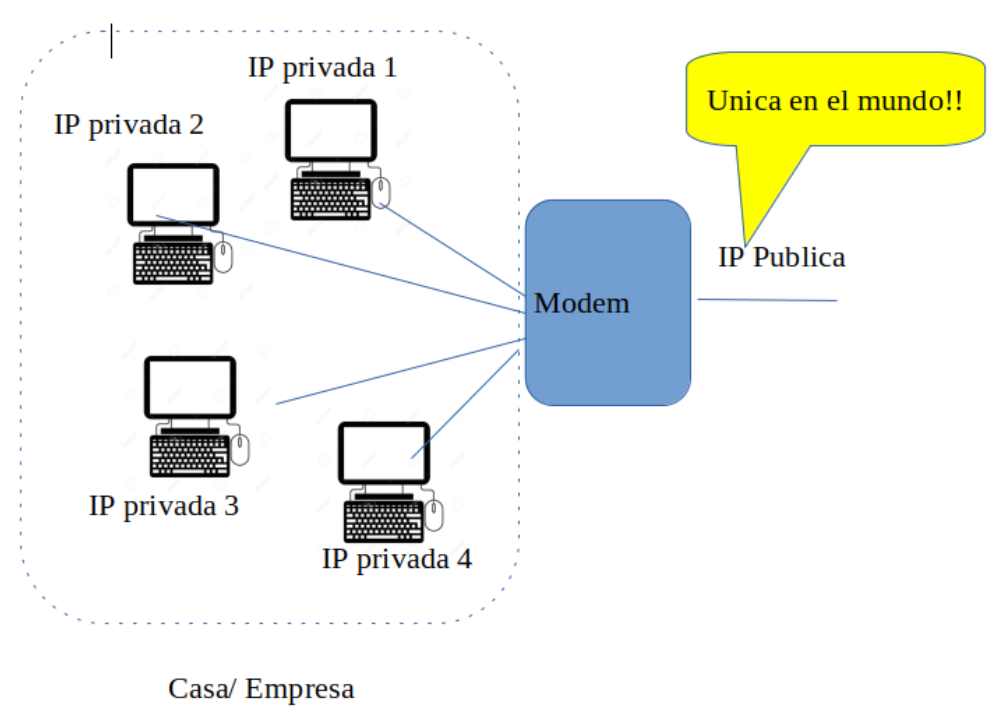
9. ARP
Introducción:
Protocolo de Resolución de Direcciones , Address Resolution Protocol.
Vamos a plantear una analogía para ver que hace el protocolo ARP.
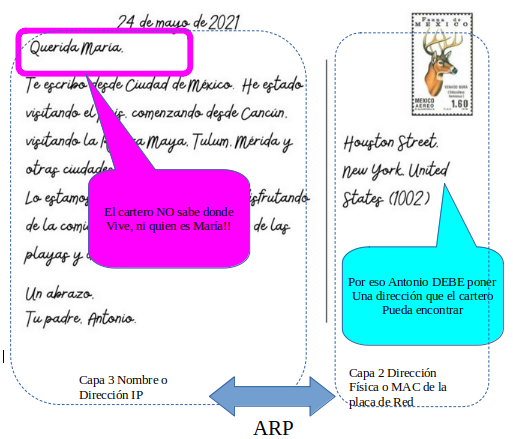 Supo
Supo
El protocolo ARP realiza una Tabla de dos entradas que vincula o relaciona direcciones IP de Capa 3 con Direcciones de Capa 1 / 2 o Físicas.

Esta Tabla NO Puede ser eterna !!( Se deja al alumno cuestionarse el por que ).
Veamos con el modelo de Capas.
Si tenemos un host X de Origen con IPx se quiere contactar con otro host de destino Y, con IPy.
Ver que conocemos las direcciones de la Capa 3, pero para enviar cualquier cosa la capa 3, la debe pasar a capa 2, pero en la capa 2 NO hay dirección IP, solo hay dirección MAC.
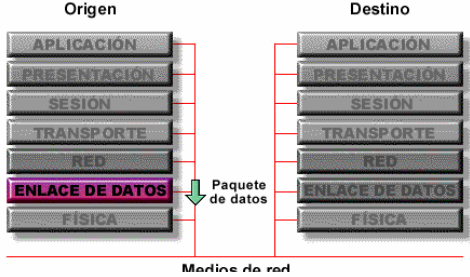
Para lograr la comunicación tiene que bajar por la pila de protocolos....capa 2 y luego capa 1.
o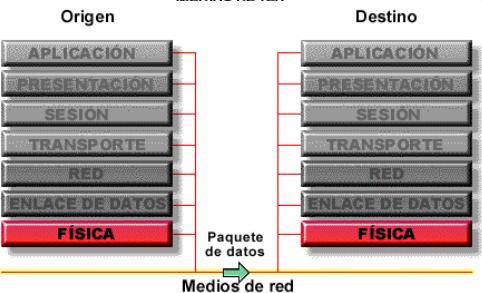
Pero llegado a la capa Física, la dirección que se tiene que usar para llegar es la Dirección Fisica.. pero NO la conozco!
Como se cual es la dirección Física (capa 2) teniendo la dirección IP (capa 3)? => ARP me ayuda a responder la pregunta.
El protocolo ARP es justamente el que consigue establecer una asociación entre las IPs y MACs de los distintos equipos. Esto se guarda en una Tabla de Cache ARP. Es un caché por que cada tanto se debe RENOVAR... si no , la asociación sería eterna... y puede ser que el equipo cambie de placa de red , por ejemplo... cambiando la IP.
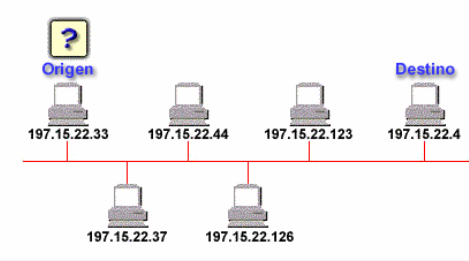
FUNCIONAMIENTO DE ARP
El Protocolo, envía un mensaje de BROADCAST a la red, consultando por la MACy , que tiene el host IPy:
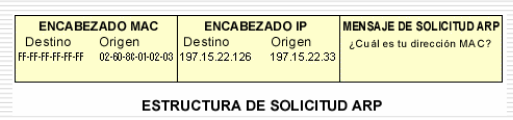
Ese paquete lo leen TODOS los equipos de la red o segmento de red, pero SOLO responde IPy, con su MACy.
Entonces el HOST va completando una Tabla.
Con el ARP Request se completa una tabla o Cache que se resetea cada 20 minutos.

La tabla ARP asocia DIrecciones IP con MAC. !!
Existen comandos en los equipos que permiten ver la tabla de ARP.
En una ventana terminal escribimos :
arp -a
Ejemplo:
El equipo con IP 197.15.22.33 quiere llegar al destino 197.15.22.126... Pero vemos que NO sabe la Dirección física o MAC.
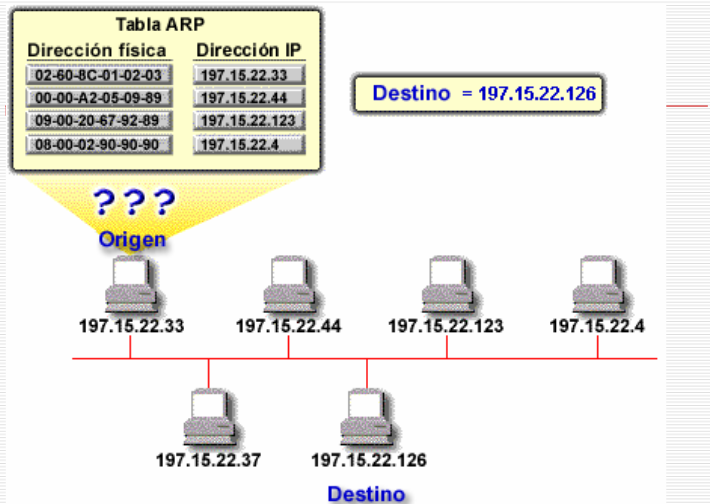
En ese caso el equipo de IP 197.15.22.33 , hace un broadcast , enviando un ARP Request, y el equipo 197.15.22.126 responde con la Dirección MAC, así el equipo IP 197.15.22.33 consigue completar la tabla con la asociación IP/MAC para el equipo de Destino. A partir de aquí se pueden comunicar por Capa 3 o capa IP.

9.1. Tramas ARP
ARP se utiliza en cuatro casos referentes a la comunicación entre dos hosts:
- Cuando dos hosts están en la misma red y uno quiere enviar un paquete a otro.
- Cuando dos hosts están sobre redes diferentes y deben usar un gateway o router para alcanzar otro host.
- Cuando un router necesita enviar un paquete a un host a través de otro router.
- Cuando un router necesita enviar un paquete a un host de la misma red.
9.2. Ataques ARP
ARP Spoofing (Suplantación de identidad)
También se conoce como suplantación de ARP. Básicamente consiste en enviar ARP falsos. Puede asociar la dirección MAC de un atacante con una dirección IP. De esta forma podría recopilar información que se envía a través de una dirección IP y controlar el tráfico.
Este tipo de ataque permite que un pirata informático pueda robar datos importantes de cualquier usuario particular o empresa en caso de un ataque exitoso. Lo pueden llevar a cabo a través de un dispositivo que previamente han atacado y controlado o incluso el suyo propio si está conectado a la red local.
Esta amenaza se podría prevenir a través de tablas ARP estáticas. Esto evita que exista caché dinámica, aunque no es algo viable en la mayoría de casos. En estos casos tendríamos que mantener una inspección constante para evitar la suplantación. Para que este tipo de ataques puedan ocurrir es necesario que el ciberdelincuente utilice ciertas herramientas como pueden ser Arpspoof o Driftnet.
También podemos relacionar esto con los ataques Man in the Middle ó ARP Poisoning. Lo que hace el atacante es interceptar todo lo que se envía, como pueden ser contraseñas o datos. Si la red está desprotegida, puede llegar a suplantar la identidad y obtener cierta información confidencial. Lo que hace el atacante literalmente es estar en medio de la comunicación, escuchando todo lo que se envía y recibe.
Otro ataque es el Secuestro de sesión: Los ataques de secuestro de sesión son de naturaleza similar a Man-in-the-Middle, excepto que el atacante no reenviará el tráfico directamente desde la máquina de la víctima a su destino previsto. En cambio, el atacante capturará un número de secuencia TCP genuino o una cookie web de la víctima y lo usará para asumir la identidad de la víctima. Esto podría usarse, por ejemplo, para acceder a la cuenta de redes sociales de un usuario objetivo si está conectado. Este ataque se inicia en capa 2, pero se utiliza en capa 4 !!.
Ataques DoS (Denial Of Service)
Otro tipo de ataque que puede afectar al protocolo ARP es lo que se conoce como denegación de servicio o DoS. En este caso un atacante va a buscar enviar una gran cantidad de solicitudes para que los sistemas, servidores o redes no puedan responder con normalidad.
Este problema va a provocar que los usuarios no puedan conectarse a la red. Para que esto ocurra deben explotar alguna vulnerabilidad que exista en el protocolo de red. Pueden hacer que durante un tiempo no puedan conectarse correctamente. Es similar a los ataques de este tipo que podemos ver contra el servidor de una web, por ejemplo, que deja de estar accesible para los visitantes.
Una vez un atacante ha logrado explotar el protocolo ARP, puede llevar a cabo ataques DDoS o de denegación de servicios distribuidos. Puede llegar a bombardear un servidor con una gran cantidad de solicitudes y que no pueda resolverlas adecuadamente.
En definitiva, el protocolo ARP sirve para resolver direcciones IPv4 a MAC.
En la materia hacemos una práctica de ataque a un Switch, en el cual se satura la tabla del Switch que asocia Puertos del Switch a Direcciones MAC, esto NO TIENE NADA QUE VER CON ARP, así que no debemos confundir.
Herramientas disponibles para este tipo de ataques
Los piratas informáticos pueden hacer uso de una serie de herramientas que están disponibles para cualquiera y que usan para la suplantación de ARP. Podemos nombrar algunas:
- Arpoison
- Netcut
- Ettercap.
9.3. Comandos para ARP.
NAME
arp - manipulate the system ARP cache
SYNOPSIS
arp [-vn] [-H type] [-i if] [-ae] [hostname]
arp [-v] [-i if] -d hostname [pub]
arp [-v] [-H type] [-i if] -s hostname hw_addr [temp]
arp [-v] [-H type] [-i if] -s hostname hw_addr [netmask nm] pub
arp [-v] [-H type] [-i if] -Ds hostname ifname [netmask nm] pub
arp [-vnD] [-H type] [-i if] -f [filename]
DESCRIPTION
Arp manipulates or displays the kernel's IPv4 network neighbour cache.
It can add entries to the table, delete one or display the current con‐
tent.
ARP stands for Address Resolution Protocol, which is used to find the
media access control address of a network neighbour for a given IPv4
Address.
MODES
arp with no mode specifier will print the current content of the table.
It is possible to limit the number of entries printed, by specifying an
hardware address type, interface name or host address.
arp -d address will delete a ARP table entry. Root or netadmin privi‐
lege is required to do this. The entry is found by IP address. If a
hostname is given, it will be resolved before looking up the entry in
the ARP table.
arp -s address hw_addr is used to set up a new table entry. The format
of the hw_addr parameter is dependent on the hardware class, but for
most classes one can assume that the usual presentation can be used.
For the Ethernet class, this is 6 bytes in hexadecimal, separated by
colons. When adding proxy arp entries (that is those with the publish
flag set) a netmask may be specified to proxy arp for entire subnets.
This is not good practice, but is supported by older kernels because it
can be useful. If the temp flag is not supplied entries will be perma‐
nent stored into the ARP cache. To simplify setting up entries for one
of your own network interfaces, you can use the arp -Ds address ifname
form. In that case the hardware address is taken from the interface
with the specified name.
OPTIONS
-v, --verbose
Tell the user what is going on by being verbose.
-n, --numeric
shows numerical addresses instead of trying to determine sym‐
bolic host, port or user names.
-H type, --hw-type type, -t type
When setting or reading the ARP cache, this optional parameter
tells arp which class of entries it should check for. The de‐
fault value of this parameter is ether (i.e. hardware code 0x01
for IEEE 802.3 10Mbps Ethernet). Other values might include
network technologies such as ARCnet (arcnet) , PROnet (pronet) ,
AX.25 (ax25) and NET/ROM (netrom).
-a Use alternate BSD style output format (with no fixed columns).
-e Use default Linux style output format (with fixed columns).
-D, --use-device
Instead of a hw_addr, the given argument is the name of an in‐
terface. arp will use the MAC address of that interface for the
table entry. This is usually the best option to set up a proxy
ARP entry to yourself.
-i If, --device If
Select an interface. When dumping the ARP cache only entries
matching the specified interface will be printed. When setting a
permanent or temp ARP entry this interface will be associated
with the entry; if this option is not used, the kernel will
guess based on the routing table. For pub entries the specified
interface is the interface on which ARP requests will be an‐
swered.
NOTE: This has to be different from the interface to which the
IP datagrams will be routed. NOTE: As of kernel 2.2.0 it is no
longer possible to set an ARP entry for an entire subnet. Linux
instead does automagic proxy arp when a route exists and it is
forwarding. See arp(7) for details. Also the dontpub option
which is available for delete and set operations cannot be used
with 2.4 and newer kernels.
-f filename, --file filename
Similar to the -s option, only this time the address info is
taken from file filename. This can be used if ARP entries for a
lot of hosts have to be set up. The name of the data file is
very often /etc/ethers, but this is not official. If no filename
is specified /etc/ethers is used as default.
The format of the file is simple; it only contains ASCII text
lines with a hostname, and a hardware address separated by
whitespace. Additionally the pub, temp and netmask flags can be
used.
In all places where a hostname is expected, one can also enter an IP
address in dotted-decimal notation.
As a special case for compatibility the order of the hostname and the
hardware address can be exchanged.
Each complete entry in the ARP cache will be marked with the C flag.
Permanent entries are marked with M and published entries have the P
flag.
EXAMPLES
/usr/sbin/arp -i eth0 -Ds 10.0.0.2 eth1 pub
This will answer ARP requests for 10.0.0.2 on eth0 with the MAC address
for eth1.
/usr/sbin/arp -i eth1 -d 10.0.0.1
Delete the ARP table entry for 10.0.0.1 on interface eth1. This will
match published proxy ARP entries and permanent entries.
FILES
/proc/net/arp
/etc/networks
/etc/hosts
/etc/ethers
SEE ALSO
rarp(8), route(8), ifconfig(8), netstat(8)
AUTHORS
Fred N. van Kempen <waltje@uwalt.nl.mugnet.org>, Bernd Eckenfels
<net-tools@lina.inka.de>.
9.4. Proxy ARP
Proxy ARP, en la que el router tiene la capacidad de responder a las solicitudes ARP para otros hosts. Retransmitir!!
De este modo es posible establecer la comunicación entre dos hosts desde diferentes subredes sin que tengan que realizarse cambios en los ajustes de red de los dispositivos.
Nota: Las solicitudes ARP NO tiene sentido que pasen de una sub-red a otra.
 ¿El alumno puede justificar esta afirmación?
¿El alumno puede justificar esta afirmación?
Si una solicitud de ARP llega a un router con un Proxy ARP activado, es este el que responde, en lugar del verdadero ordenador de destino. Para ello transmite su propia dirección MAC, con lo que también recibe los paquetes de datos del remitente. Posteriormente, el router le transmite la información al host de destino con ayuda de los datos de la caché de ARP.
9.5. Ejercicio.

Ejercicio 1:
Se propone al alumno.
1) Abrir una consola o terminal y ejecutar el comando para ver la tabla de ARP del equipo.
El Linux la sintaxis es arp -a

2) Consultar con su compañero , la IP del equipo , en Linux, para ver la configuración de IP del equipo por consola es : ifconfig, en Windows ipconfig.
3 ) Ejecutar el comando ping a la IP de su compañero.
4) Listar la tabla de arp, se debería encontrar una entrada nueva que tiene la IP del compañero y la MAC del equipo del compañero.
Ejercicio 2:
- Desde la PC ver la tabla de ARP.
- Hacer un ping a dns 1.1.1.1
- Ver si aparece la MAC de esta IP en la tabla ARP, y justificar la respuesta.
9.6. Videos
10. Subredes
En el direccionamiento con clase, los primeros ocho bits de una dirección IP definían la red de la que formaba parte un host determinado ( esto es lo que vimos en capítulos anteriores ).
A medida que Internet creció, la ineficiencia de asignar direcciones IP de esta manera se convirtió en un problema. Durante los primeros días de Internet, el espacio de direcciones aparentemente ilimitado permitía Direcciones IP que se asignarán a una organización en función de su solicitud en lugar de su necesidad real. Como resultado, las direcciones fueron asignadas libremente a quienes solicitaron sin preocuparse por el eventual agotamiento del espacio de direcciones IP.
En pocas palabras: necesitábamos una forma de asignar direcciones de manera más eficiente y ajustadas a las necesidades.
La decisión de estandarizar un espacio de direcciones de 32 bits significó que solo había 232 (4,294,967,296) Direcciones IPv4 disponibles. Una decisión de aumentar la cantidad de bits de direcciones daría más grande el espacio de direcciones y aumentaría exponencialmente el número de direcciones por lo tanto eliminando el problema actual de escasez de direcciones ( esto se hace en IPV6 ).
Los límites de octetos A, B y C con clase fueron fáciles de entender e implementar, pero no fomentaron la asignación eficiente de un espacio de direcciones finito. Un /24, que admite 254 hosts, es demasiado pequeño mientras que un /16, que admite 65.534 hosts, es demasiado grande. En el pasado, Internet ha asignado sitios con varios cientos de hosts, una sola dirección /16 en lugar de un par de /24 direcciones. Desafortunadamente, esto ha resultado en un agotamiento prematuro del /16
espacio de direcciones de red. Las únicas direcciones fácilmente disponibles para medianas organizaciones son /24 que tienen el impacto potencialmente negativo de aumentar el tamaño de la tabla de enrutamiento de Internet global derivado del crecimiento de Internet, es que la cantidad de entradas en la tabla de ruteo crecía, la tabla de ruteo de un Router , sería una fila , donde dice: Para esta red (IP), salir por esta interface.
Como la cantidad de redes aumentaba, también aumentaban las filas de las tablas de los routers..
11. Introducción
Subredes y máscaras de subred
Desde afuera SOLO hay una red !!
El router debe conocer las subredes a las que está conectado.
11.1. Subnetting
En 1985, RFC 950 definió un procedimiento estándar para admitir la subred, o división, de un solo número de red Clase A, B o C en partes más pequeñas. La división en subredes fue introducido para superar algunos de los problemas que mencionamos, para solucionar esto se comienza introduciendo una nueva jerarquía de direccionamiento, subdividiendo el campo de host en dos, como se puede ver en la siguiente imagen:
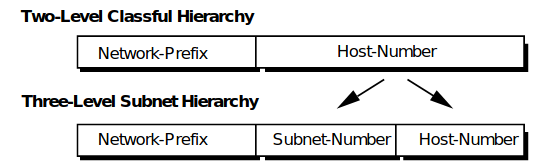 Figura 1
Figura 1use el mismo prefijo de red pero diferentes números de subred.
La división en subredes superó el problema, asignando a cada organización uno (o como máximo unos pocos) número(s) de red del espacio de direcciones IPv4. La organización fue luego libre para asignar un número de subred distinto para cada una de sus redes internas.
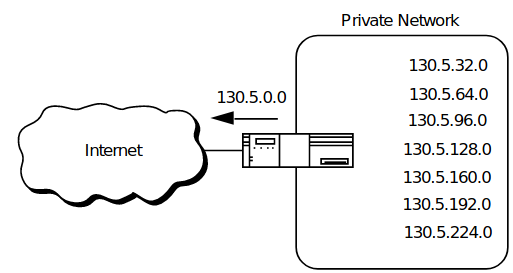
Que problemas solucionó subnetting?
1) Achicar entradas en tabla de ruteo.( este siempre se olvida!)
2) Optimizar el uso de direcciones IP
11.2. Prefijo extendido de Red
Los enrutadores de Internet usan solo el prefijo de red de la dirección de destino para enrutar el tráfico a un entorno dividido en subredes.
Los enrutadores dentro del entorno dividido en subredes utilizan el prefijo de red para enrutar el tráfico entre las subredes individuales.
El prefijo de red se compone con el campo de red con clase y el número de subred y se representa con una Barra al finalizar la notación decimal.
11.3. Diseño
El despliegue de un plan de direccionamiento requiere una cuidadosa reflexión por parte del administrador de red. Hay cuatro preguntas claves que deben responderse antes de llevar a cabo el diseño:
1) ¿Cuántas subredes totales necesita la organización hoy?
2) ¿Cuántas subredes totales necesitará la organización en el futuro?
3) ¿Cuántos hosts hay actualmente en la subred más grande de la organización?
4) ¿Cuántos hosts habrá en la subred más grande de la organización en el futuro?
Veamos unos Ejemplos de como resolver estas cuestiones planeadas.
11.4. Ejemplos de Subredes.
Una organización tiene como ip asignado la dirección 193.1.1.0/24. Internamente se necesitan definir 6 subredes. No se utilizarán más de 25 hosts por subred.
1) determinar cantidad de bits requeridos en la máscara.
con 2 bits tendremos 22 = 4 subredes. mientras que con 3 bits tendremos 23=8 subredes. por lo que podemos adoptar 3 bits. y nuestra mascara de red sería 255.255.255.224 o simplemente /27
2) comprobar cantidad de host.
para los host tendremos entonces 8 -3 bits disponibles. por lo que tendriamos 25 = 32 direcciones posibles, descontando 2 direcciones ("todos los bits en 0" reservada y "todos los bits en 1" dirección de broadcast) los posibles host quedan reducidos a 30, pudiendo tener entonces los 25 solicitados y 5 direcciones más a futuro.

3) definir direcciones de las subredes
utilizando entonces los 3 bits definidos, vamos a tener las siguientes direcciones.
como vemos tendremos un total de 8 subredes. 2 más de las requeridas.

4) definir direcciones posibles de los hosts
Por ejemplo para la subred Nro 6 tenemos los siguientes 30 hosts:

5) definir direcciones de broadcast (multidifusión)
Para el caso de la subred 6 tendremos entonces rellenando los bits de host con todos 1

nótese que la dirección de broadcast de la subred 6 es exactamente 1 bit menos que la dirección base de la subred 7 (192.1.1.224)
RESUMIENDO TENEMOS ENTONCES LO SIGUIENTE:

11.5. Ejercicios de Subredes
Para cada dirección dada determinar la máscara de subred, la dirección de GW, la primer y última dirección utilizable de esa subred.
- 172.16.18.10/18
- 172.28.26.12/13
- 192.168.200.100/27
- 10.10.229.130/21
- 10.113.30.38.22
11.6. Ejercicios IP - Teoría + práctica
Unidad CAPA 3 – RED:
SECCIÓN TEORÍA:
1- Describa los objetivos principales de la red primitiva ARPANET
2- Dada una X cantidad de paquetes que “viajan” por internet, ¿usan la misma ruta para llegar?
3- ¿Qué diferencia existe entre una dirección física y una lógica?
4- ¿Qué función cumple el protocolo IP?
5- Describa brevemente el proceso de envío, transmisión y llegada de paquetes en una red de conmutación de paquetes.
6- ¿Cuántos tipos de Clases IP existen y en qué se diferencian cada una de ellas?
7- ¿Por qué es Necesario Realizar una división de redes o SUBNETTING? ¿Qué ventajas obtiene de realizar este mecanismo?
8- ¿Cuál es la función de la IP 127.0.0.1?
9- En un datagrama IP, ¿ qué función cumple el campo TTL ?
SECCIÓN PRÁCTICA:
Ejercicio 01:
a)
Analice cada una de las siguientes direcciones IPv4 y determine si son válidas o no. Indique a
qué clase pertenece y si es pública o privada. En el caso de no ser válida explique por qué.
• 192.168.1.5
• 192.256.5.10
• 240.1.10.10
• 100.100.15.15
b)
Indique que máscaras son válidas y cuáles no. ¿Por qué?
• 255.255.0.0
• 255.256.255.0
• 254.255.255.0
• 255.255.0.255
Ejercicio 02:
Dada la red 149.250.0.0 y la máscara de subred 255.255.255.0, defina
- ¿Cuántas redes disponibles hay?
- Escriba el número de la primera y última red disponible.
- Defina las direcciones de broadcast de la primera y última dirección disponible.
Ejercicio 03:
Se tiene la siguiente dirección 220.120.120.10/27. ¿Cuál es la subred a la que pertenece la dirección IP?
Usted tiene la siguiente dirección IP 192.255.15.75/28 ¿Cuántos IP para host y cuantas subredes como máximo son posibles?
Ejercicio 04:
Sea la dirección de una subred 150.214.141.0, con una máscara de red 255.255.255.0
Comprobar cuáles de estas direcciones no pertenecen a dicha red:
150.214.141.128
150.214.141.138
150.214.142.23
Ejercicio 05:
Considerando la siguiente IP 172.16.45.14/30. ¿Cuál es la dirección de la subred a la cual pertenece ese nodo? (MARQUE LA CORRECTA DE LAS OPCIONES, LUEGO DE EXPONER LA SOLUCIÓN)
A. 172.16.45.0
B. 172.16.45.4
C. 172.16.45.8
D. 172.16.45.12
E. 172.16.45.18
F. 172.16.0.0
Ejercicio 06:
Una determinada organización posee la siguiente IP 172.12.0.0. Se contrata a un administrador de red y se le plantea la necesidad de dividir en subredes que soporten un máximo de 459 hosts por subred, procurando mantener en su máximo el número de subredes disponibles. Determina la máscara que se deberá utilizar.
Ejercicio 07:
Considerando la dirección IP 172.50.10.07/16 propiedad de la empresa NATURALIVE. De manera inicial se plantearon 25 subredes. Con un mínimo de 900 hosts por subred. Se proyecta un crecimiento en los próximos años de un total de 55 subredes. Determine, ¿Qué mascara de subred se deberá utilizar?
12. Localhost.
¿Que es el localhost?
Todo localhost tiene asignada la dirección IP 127.0.0.1 (o::1 en IPv6), también llamada dirección IP de loopback o bucle reverso.
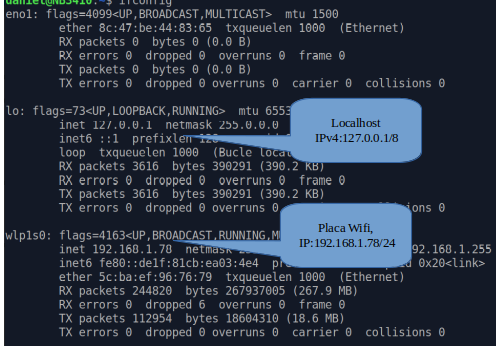
Mas detallado:
13. DHCP
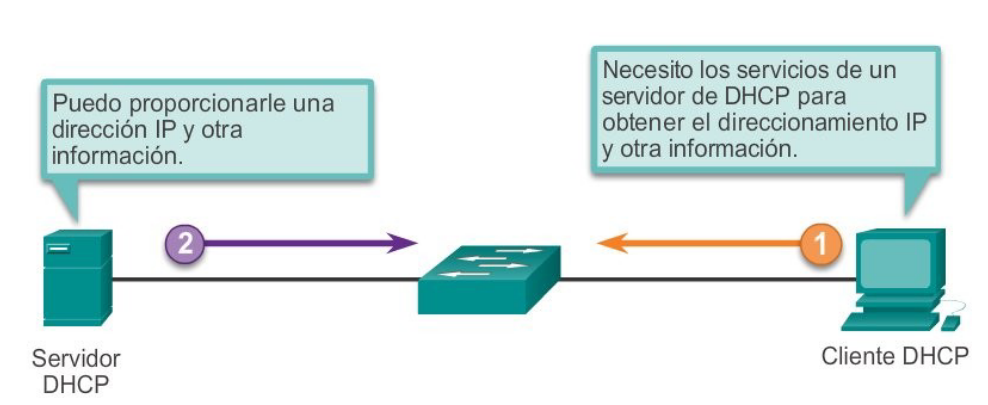
DHCP v.4
Asigna direcciones IPv4 y otra información de configuración de red en forma dinámica. Dado que los clientes de escritorio suelen componer gran parte de los nodos de red, DHCPv4 es una herramienta extremadamente útil para los administradores de red y que ahorra mucho tiempo.
Existen 3 mecanismos:
● Asignación manual: el administrador asigna una dirección IPv4 preasignada al cliente, y DHCP v.4 comunica solo la dirección IPv4 al dispositivo.
● Asignación automática: DHCP v.4 asigna automáticamente una dirección IPv4 estática de forma permanente a un dispositivo y la selecciona de un conjunto de direcciones disponibles. No hay arrendamiento, y la dirección se asigna de forma permanente al dispositivo.
● Asignación dinámica: DHCP v.4 asigna dinámicamente, o arrienda, una dirección IPv4 de un conjunto de direcciones durante un período limitado elegido por el servidor o hasta que el cliente ya no necesite la dirección.
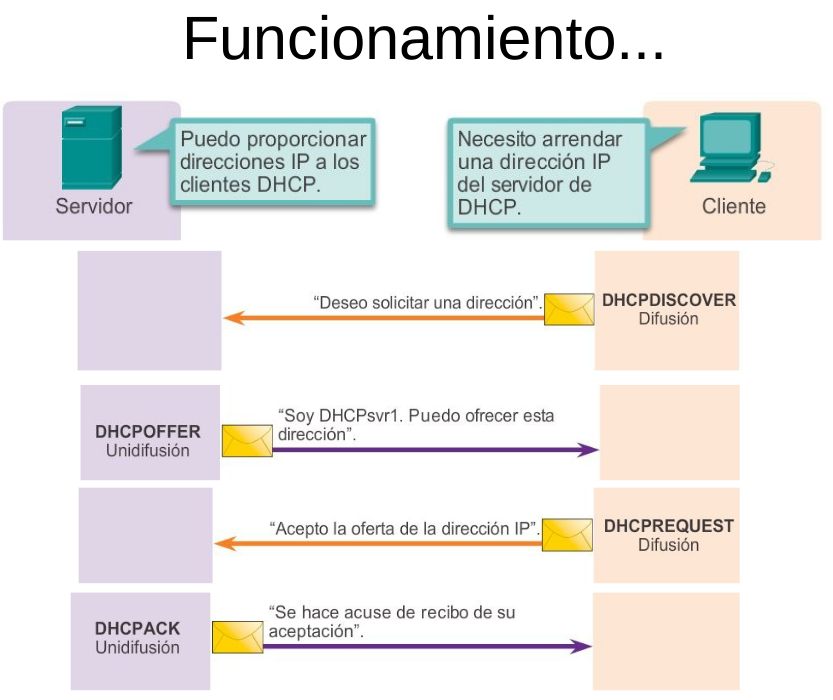
La asignación dinámica es el mecanismo DHCP v.4 que se utiliza más comúnmente y es el eje de esta sección. Al utilizar la asignación dinámica, los clientes arriendan ( “alquilan”) la información del servidor durante un período definido administrativamente.
Los administradores configuran los servidores de DHCP v.4 para establecer los arrendamientos, a fin de que caduquen a distintos intervalos. El arrendamiento típicamente dura de 24 horas a una semana o más. Cuando caduca el arrendamiento, el cliente debe solicitar otra dirección, aunque generalmente se le vuelve a asignar la misma.
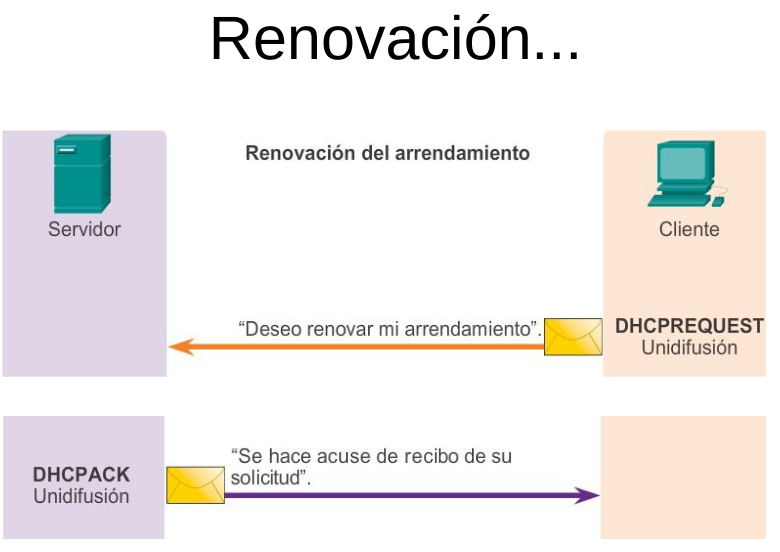
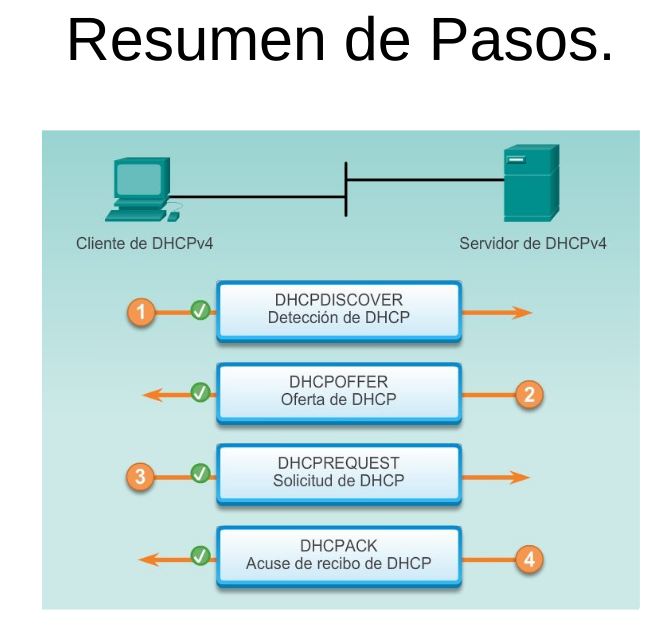
Formato del Mensaje DHCP:
El formato del mensaje DHCPv4 se utiliza para todas las transacciones DHCPv4. Los mensajes DHCPv4 se encapsulan dentro del protocolo de transporte UDP ( capa 4 ).
Los mensajes DHCPv4 que se envían desde el cliente utilizan el puerto de origen UDP 68 y el puerto de destino 67. Los mensajes DHCPv4 que se envían del servidor al cliente utilizan el puerto de origen UDP 67 y el puerto de destino 68.
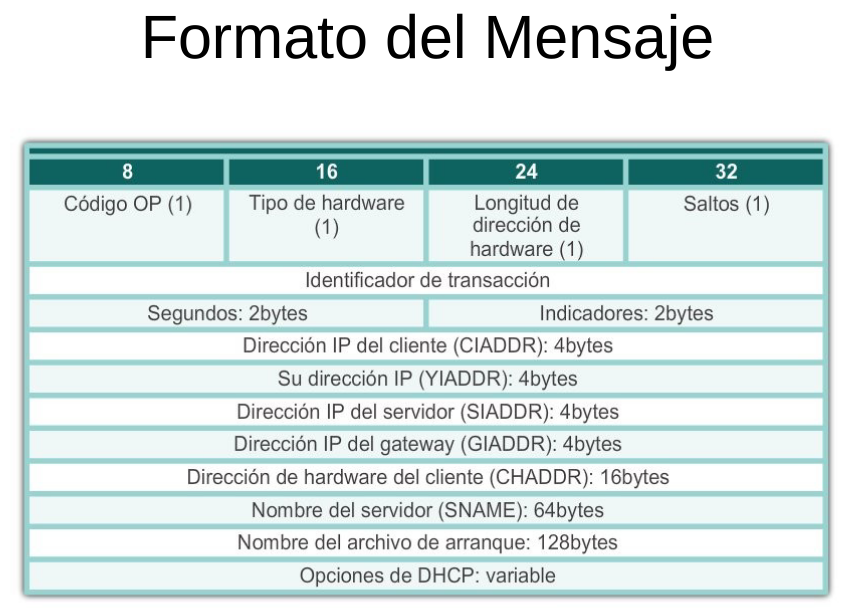
●Código de operación (OP): especifica el tipo de mensaje general. El valor 1 indica un mensaje de solicitud y el valor 2 es un mensaje de respuesta.
●Tipo de hardware: identifica el tipo de hardware que se utiliza en la red. Por ejemplo, 1 es Ethernet, 15 es Frame Relay y 20 es una línea serial. Estos son los mismos códigos que se utilizan en mensajes ARP.
●Longitud de dirección de hardware: especifica la longitud de la dirección.
●Saltos: controla el reenvío de mensajes. Un cliente establece en 0 antes de transmitir una solicitud.
●Identificador de transacción: utiliza el cliente para hacer coincidir la solicitud con respuestas recibidas de los servidores de DHCPv4.
●Segundos: identifica la cantidad de segundos transcurridos desde que un cliente comenzó a intentar adquirir o renovar un arrendamiento. Utilizan los servidores de DHCPv4 para priorizar respuestas cuando hay varias solicitudes del cliente pendientes.
●Indicadores: Es utilizado por un cliente que no conoce su dirección IPv4 cuando envía una solicitud. Se emplea solo uno de los 16 bits, que es el indicador de difusión. El valor 1 en este campo le indica al servidor de DHCPv4 o al agente de retransmisión que recibe la solicitud que la respuesta se debe enviar como una difusión.
●Dirección IP del cliente: la utiliza un cliente durante la renovación del arrendamiento cuando la dirección del cliente es válida y utilizable, no durante el proceso de adquisición de una dirección. El cliente coloca su propia dirección IPv4 en este campo solamente si tiene una dirección IPv4 válida mientras se encuentra en el estado vinculado. De lo contrario, establece el campo en 0.
●Su dirección IP: la utiliza el servidor para asignar una dirección IPv4 al cliente.
●Dirección IP del servidor: la utiliza el servidor para identificar la dirección del servidor que debe emplear el cliente para el próximo paso en el proceso "bootstrap" (llamado también BOOTP), que puede ser, o no, el servidor que envía esta respuesta. El servidor emisor siempre incluye su propia dirección IPv4 en un campo especial llamado opción DHCPv4 Server Identifier (Identificador de servidores DHCPv4).
●Dirección IP del gateway: enruta los mensajes DHCPv4 cuando intervienen los agentes de retransmisión DHCPv4. La dirección del gateway facilita las comunicaciones de las solicitudes y respuestas de DHCPv4 entre el cliente y un servidor que se encuentran en distintas subredes o redes.
●Dirección de hardware del cliente: especifica la capa física del cliente.
●Nombre del servidor: lo utiliza el servidor que envía un mensaje "DHCPOFFER" o "DHCPACK." El servidor puede, de manera optativa, colocar su nombre en este campo. Puede tratarse de un simple apodo de texto o un nombre de dominio DNS, como dhcpserver.netacad.net.
.●Nombre del archivo de arranque: lo utiliza un cliente de manera optativa para solicitar un determinado tipo de archivo de arranque en un mensaje "DHCPDISCOVER". Lo utiliza un servidor en un DHCPOFFER para especificar completamente un directorio de archivos y un nombre de archivo de arranque.
●Opciones de DHCP: contiene las opciones de DHCP, incluidos varios parámetros requeridos para el funcionamiento básico de DHCP. Este campo es de longitud variable. Tanto el cliente como el servidor pueden utilizarlo.
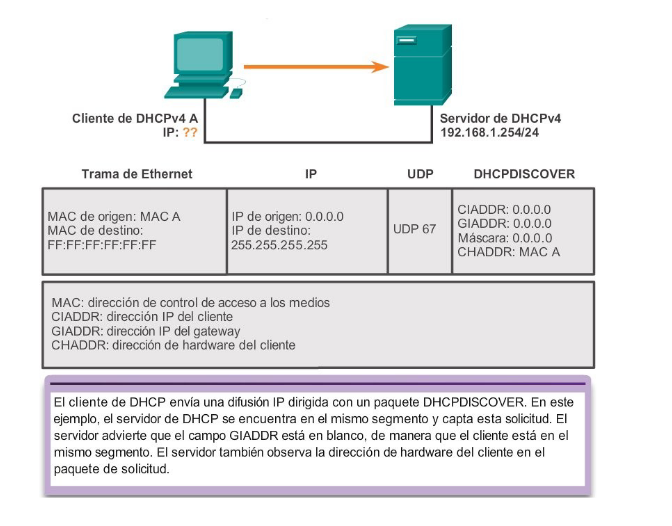
Mensaje Discover DHCP v4
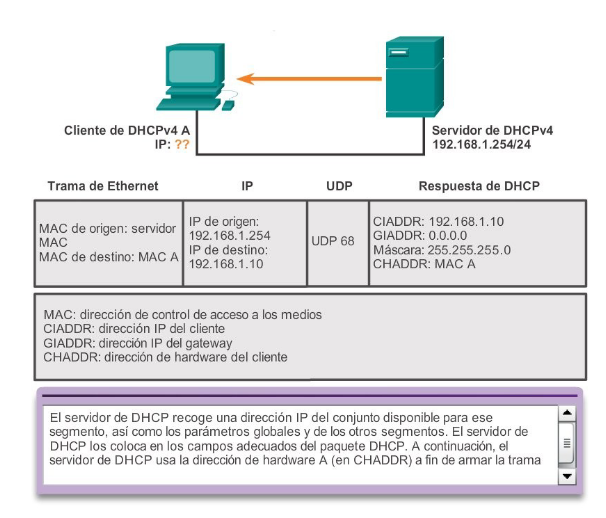
Mensaje Offer DHCP v4
14. ICMP v.4
.
ICMP Accesibilidad al Host
ICMP : Internet Control Message Protocol - (Protocolo de mensajes de control de Internet).
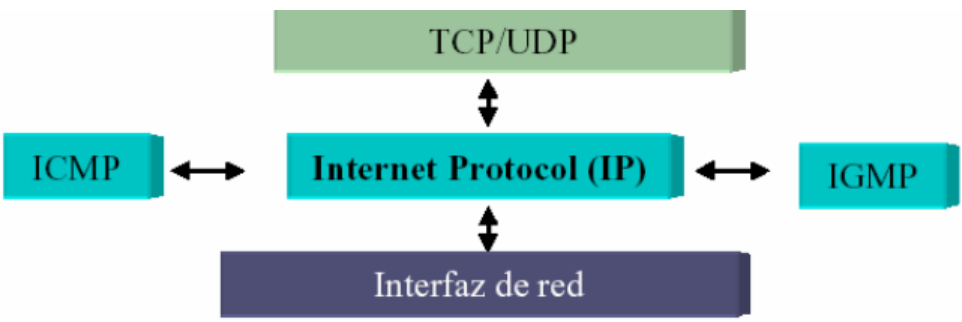
IGMP es Internet Group Management Protocol (Protocolo de Gestión de Grupos de Internet) , no confundir con ICMP. IGMP lo veremos mas adelante. A modo de anticipo:
El IGMP es un protocolo que permite que varios dispositivos compartan una dirección IP para que todos puedan recibir los mismos datos. El IGMP es un protocolo en la capa de red que se utiliza para configurar la multidifusión en las redes que utilizan el protocolo de Internet versión 4 (IPv4). En concreto, IGMP permite que los dispositivos puedan unirse a un grupo de multidifusión.
Los mensajes de error ICMP se envían a través de la red en forma de datagramas, recordemos que un datagrama es la UDP (Unit Data Protocol - Unidad de Datos de Protocolo ) capa 3 (Red) como cualquier otro dato.
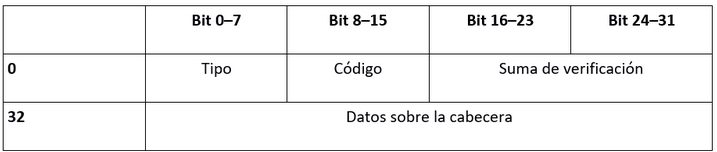
- Datos
- Código
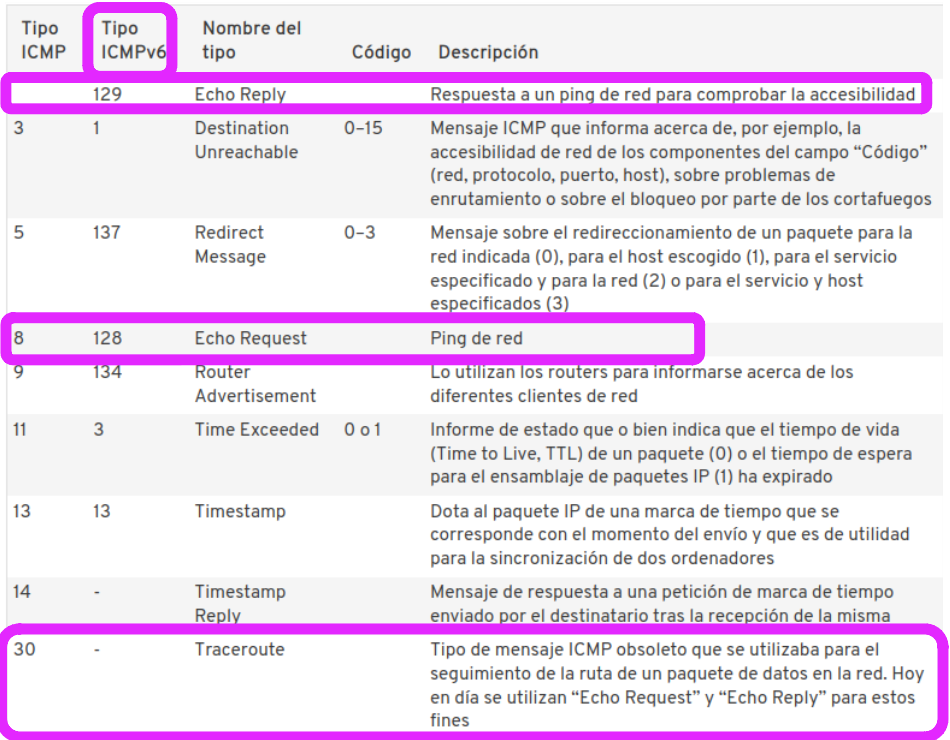
Comando PING.
- Envío de paquetes ICMP de solicitud (ICMP Echo Request).
- Respuesta (ICMP Echo Reply).
The response for 'www.google.com' using IPv4 is:
PING www.google.com (142.250.191.68) 56(84) bytes of data.
64 bytes from nuq04s43-in-f4.1e100.net (142.250.191.68): icmp_seq=1 ttl=120 time=1.29 ms
64 bytes from nuq04s43-in-f4.1e100.net (142.250.191.68): icmp_seq=2 ttl=120 time=1.42 ms
64 bytes from nuq04s43-in-f4.1e100.net (142.250.191.68): icmp_seq=3 ttl=120 time=1.40 ms
64 bytes from nuq04s43-in-f4.1e100.net (142.250.191.68): icmp_seq=4 ttl=120 time=1.41 ms
64 bytes from nuq04s43-in-f4.1e100.net (142.250.191.68): icmp_seq=5 ttl=120 time=1.39 ms
--- www.google.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4008ms
rtt min/avg/max/mdev = 1.296/1.387/1.427/0.046 ms
Algo mas gráfico se puede ver en este dibujo, que se hace ping en una red local privada.
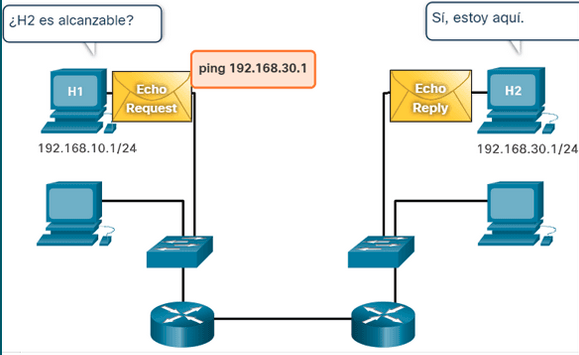
Observación:
- Para este ejemplo (antes de poder hacer el ping) se realizaron dos acciones:
- DNS, se resuelve cual es la IP de www.google.com.
- Se determina la MAC del Gateway para poner en los paquetes de capa 3 que van Fuera de la Red, esto se hace con algunos o todos los métodos: ARP, DCHP, Subnetting.
- Los mensajes de error pueden contener errores. Si hay un error en un datagrama que transporta un mensaje ICMP, no se envía ningún mensaje de error para evitar el efecto "bola de nieve" o cascada en el caso de un incidente en la red.
15. Manual de Ping.
PING(8) iputils PING(8)
NAME
ping - send ICMP ECHO_REQUEST to network hosts
SYNOPSIS
ping [-aAbBdDfhLnOqrRUvV46] [-c count] [-F flowlabel] [-i interval]
[-I interface] [-l preload] [-m mark] [-M pmtudisc_option]
[-N nodeinfo_option] [-w deadline] [-W timeout] [-p pattern]
[-Q tos] [-s packetsize] [-S sndbuf] [-t ttl]
[-T timestamp option] [hop...] {destination}
DESCRIPTION
ping uses the ICMP protocol's mandatory ECHO_REQUEST datagram to elicit
an ICMP ECHO_RESPONSE from a host or gateway. ECHO_REQUEST datagrams
(“pings”) have an IP and ICMP header, followed by a struct timeval and
then an arbitrary number of “pad” bytes used to fill out the packet.
ping works with both IPv4 and IPv6. Using only one of them explicitly
can be enforced by specifying -4 or -6.
ping can also send IPv6 Node Information Queries (RFC4620).
Intermediate hops may not be allowed, because IPv6 source routing was
deprecated (RFC5095).
OPTIONS
-4
Use IPv4 only.
-6
Use IPv6 only.
-a
Audible ping.
-A
Adaptive ping. Interpacket interval adapts to round-trip time, so
that effectively not more than one (or more, if preload is set)
unanswered probe is present in the network. Minimal interval is
200msec unless super-user. On networks with low RTT this mode is
essentially equivalent to flood mode.
-b
Allow pinging a broadcast address.
-B
Do not allow ping to change source address of probes. The address
is bound to one selected when ping starts.
-c count
Stop after sending count ECHO_REQUEST packets. With deadline
option, ping waits for count ECHO_REPLY packets, until the timeout
expires.
-d
Set the SO_DEBUG option on the socket being used. Essentially, this
socket option is not used by Linux kernel.
-D
Print timestamp (unix time + microseconds as in gettimeofday)
before each line.
-f
Flood ping. For every ECHO_REQUEST sent a period “.” is printed,
while for every ECHO_REPLY received a backspace is printed. This
provides a rapid display of how many packets are being dropped. If
interval is not given, it sets interval to zero and outputs packets
as fast as they come back or one hundred times per second,
whichever is more. Only the super-user may use this option with
zero interval.
-F flow label
IPv6 only. Allocate and set 20 bit flow label (in hex) on echo
request packets. If value is zero, kernel allocates random flow
label.
-h
Show help.
-i interval
Wait interval seconds between sending each packet. Real number
allowed with dot as a decimal separator (regardless locale setup).
The default is to wait for one second between each packet normally,
or not to wait in flood mode. Only super-user may set interval to
values less than 2 ms.
-I interface
interface is either an address, an interface name or a VRF name. If
interface is an address, it sets source address to specified
interface address. If interface is an interface name, it sets
source interface to specified interface. If interface is a VRF
name, each packet is routed using the corresponding routing table;
in this case, the -I option can be repeated to specify a source
address. NOTE: For IPv6, when doing ping to a link-local scope
address, link specification (by the '%'-notation in destination, or
by this option) can be used but it is no longer required.
-l preload
If preload is specified, ping sends that many packets not waiting
for reply. Only the super-user may select preload more than 3.
-L
Suppress loopback of multicast packets. This flag only applies if
the ping destination is a multicast address.
-m mark
use mark to tag the packets going out. This is useful for variety
of reasons within the kernel such as using policy routing to select
specific outbound processing.
-M pmtudisc_opt
Select Path MTU Discovery strategy. pmtudisc_option may be either
do (prohibit fragmentation, even local one), want (do PMTU
discovery, fragment locally when packet size is large), or dont (do
not set DF flag).
-N nodeinfo_option
IPv6 only. Send ICMPv6 Node Information Queries (RFC4620), instead
of Echo Request. CAP_NET_RAW capability is required.
help
Show help for NI support.
name
Queries for Node Names.
ipv6
Queries for IPv6 Addresses. There are several IPv6 specific
flags.
ipv6-global
Request IPv6 global-scope addresses.
ipv6-sitelocal
Request IPv6 site-local addresses.
ipv6-linklocal
Request IPv6 link-local addresses.
ipv6-all
Request IPv6 addresses on other interfaces.
ipv4
Queries for IPv4 Addresses. There is one IPv4 specific flag.
ipv4-all
Request IPv4 addresses on other interfaces.
subject-ipv6=ipv6addr
IPv6 subject address.
subject-ipv4=ipv4addr
IPv4 subject address.
subject-name=nodename
Subject name. If it contains more than one dot, fully-qualified
domain name is assumed.
subject-fqdn=nodename
Subject name. Fully-qualified domain name is always assumed.
-n
Numeric output only. No attempt will be made to lookup symbolic
names for host addresses.
-O
Report outstanding ICMP ECHO reply before sending next packet. This
is useful together with the timestamp -D to log output to a
diagnostic file and search for missing answers.
-p pattern
You may specify up to 16 “pad” bytes to fill out the packet you
send. This is useful for diagnosing data-dependent problems in a
network. For example, -p ff will cause the sent packet to be filled
with all ones.
-q
Quiet output. Nothing is displayed except the summary lines at
startup time and when finished.
-Q tos
Set Quality of Service -related bits in ICMP datagrams. tos can be
decimal (ping only) or hex number.
In RFC2474, these fields are interpreted as 8-bit Differentiated
Services (DS), consisting of: bits 0-1 (2 lowest bits) of separate
data, and bits 2-7 (highest 6 bits) of Differentiated Services
Codepoint (DSCP). In RFC2481 and RFC3168, bits 0-1 are used for
ECN.
Historically (RFC1349, obsoleted by RFC2474), these were
interpreted as: bit 0 (lowest bit) for reserved (currently being
redefined as congestion control), 1-4 for Type of Service and bits
5-7 (highest bits) for Precedence.
-r
Bypass the normal routing tables and send directly to a host on an
attached interface. If the host is not on a directly-attached
network, an error is returned. This option can be used to ping a
local host through an interface that has no route through it
provided the option -I is also used.
-R
ping only. Record route. Includes the RECORD_ROUTE option in the
ECHO_REQUEST packet and displays the route buffer on returned
packets. Note that the IP header is only large enough for nine such
routes. Many hosts ignore or discard this option.
-s packetsize
Specifies the number of data bytes to be sent. The default is 56,
which translates into 64 ICMP data bytes when combined with the 8
bytes of ICMP header data.
-S sndbuf
Set socket sndbuf. If not specified, it is selected to buffer not
more than one packet.
-t ttl
ping only. Set the IP Time to Live.
-T timestamp option
Set special IP timestamp options. timestamp option may be either
tsonly (only timestamps), tsandaddr (timestamps and addresses) or
tsprespec host1 [host2 [host3 [host4]]] (timestamp prespecified
hops).
-U
Print full user-to-user latency (the old behaviour). Normally ping
prints network round trip time, which can be different f.e. due to
DNS failures.
-v
Verbose output. Do not suppress DUP replies when pinging multicast
address.
-V
Show version and exit.
-w deadline
Specify a timeout, in seconds, before ping exits regardless of how
many packets have been sent or received. In this case ping does not
stop after count packet are sent, it waits either for deadline
expire or until count probes are answered or for some error
notification from network.
-W timeout
Time to wait for a response, in seconds. The option affects only
timeout in absence of any responses, otherwise ping waits for two
RTTs. Real number allowed with dot as a decimal separator
(regardless locale setup). 0 means infinite timeout.
When using ping for fault isolation, it should first be run on the
local host, to verify that the local network interface is up and
running. Then, hosts and gateways further and further away should be
“pinged”. Round-trip times and packet loss statistics are computed. If
duplicate packets are received, they are not included in the packet
loss calculation, although the round trip time of these packets is used
in calculating the minimum/average/maximum/mdev round-trip time
numbers.
Population standard deviation (mdev), essentially an average of how far
each ping RTT is from the mean RTT. The higher mdev is, the more
variable the RTT is (over time). With a high RTT variability, you will
have speed issues with bulk transfers (they will take longer than is
strictly speaking necessary, as the variability will eventually cause
the sender to wait for ACKs) and you will have middling to poor VoIP
quality.
When the specified number of packets have been sent (and received) or
if the program is terminated with a SIGINT, a brief summary is
displayed. Shorter current statistics can be obtained without
termination of process with signal SIGQUIT.
If ping does not receive any reply packets at all it will exit with
code 1. If a packet count and deadline are both specified, and fewer
than count packets are received by the time the deadline has arrived,
it will also exit with code 1. On other error it exits with code 2.
Otherwise it exits with code 0. This makes it possible to use the exit
code to see if a host is alive or not.
This program is intended for use in network testing, measurement and
management. Because of the load it can impose on the network, it is
unwise to use ping during normal operations or from automated scripts.
ICMP PACKET DETAILS
An IP header without options is 20 bytes. An ICMP ECHO_REQUEST packet
contains an additional 8 bytes worth of ICMP header followed by an
arbitrary amount of data. When a packetsize is given, this indicates
the size of this extra piece of data (the default is 56). Thus the
amount of data received inside of an IP packet of type ICMP ECHO_REPLY
will always be 8 bytes more than the requested data space (the ICMP
header).
If the data space is at least of size of struct timeval ping uses the
beginning bytes of this space to include a timestamp which it uses in
the computation of round trip times. If the data space is shorter, no
round trip times are given.
DUPLICATE AND DAMAGED PACKETS
ping will report duplicate and damaged packets. Duplicate packets
should never occur, and seem to be caused by inappropriate link-level
retransmissions. Duplicates may occur in many situations and are rarely
(if ever) a good sign, although the presence of low levels of
duplicates may not always be cause for alarm.
Damaged packets are obviously serious cause for alarm and often
indicate broken hardware somewhere in the ping packet's path (in the
network or in the hosts).
TRYING DIFFERENT DATA PATTERNS
The (inter)network layer should never treat packets differently
depending on the data contained in the data portion. Unfortunately,
data-dependent problems have been known to sneak into networks and
remain undetected for long periods of time. In many cases the
particular pattern that will have problems is something that doesn't
have sufficient “transitions”, such as all ones or all zeros, or a
pattern right at the edge, such as almost all zeros. It isn't
necessarily enough to specify a data pattern of all zeros (for example)
on the command line because the pattern that is of interest is at the
data link level, and the relationship between what you type and what
the controllers transmit can be complicated.
This means that if you have a data-dependent problem you will probably
have to do a lot of testing to find it. If you are lucky, you may
manage to find a file that either can't be sent across your network or
that takes much longer to transfer than other similar length files. You
can then examine this file for repeated patterns that you can test
using the -p option of ping.
TTL DETAILS
The TTL value of an IP packet represents the maximum number of IP
routers that the packet can go through before being thrown away. In
current practice you can expect each router in the Internet to
decrement the TTL field by exactly one.
The TCP/IP specification states that the TTL field for TCP packets
should be set to 60, but many systems use smaller values (4.3 BSD uses
30, 4.2 used 15).
The maximum possible value of this field is 255, and most Unix systems
set the TTL field of ICMP ECHO_REQUEST packets to 255. This is why you
will find you can “ping” some hosts, but not reach them with telnet(1)
or ftp(1).
In normal operation ping prints the TTL value from the packet it
receives. When a remote system receives a ping packet, it can do one of
three things with the TTL field in its response:
• Not change it; this is what Berkeley Unix systems did before the
4.3BSD Tahoe release. In this case the TTL value in the received
packet will be 255 minus the number of routers in the round-trip
path.
• Set it to 255; this is what current Berkeley Unix systems do. In
this case the TTL value in the received packet will be 255 minus
the number of routers in the path from the remote system to the
pinging host.
• Set it to some other value. Some machines use the same value for
ICMP packets that they use for TCP packets, for example either 30
or 60. Others may use completely wild values.
BUGS
• Many Hosts and Gateways ignore the RECORD_ROUTE option.
• The maximum IP header length is too small for options like
RECORD_ROUTE to be completely useful. There's not much that can be
done about this, however.
• Flood pinging is not recommended in general, and flood pinging
the broadcast address should only be done under very controlled
conditions.
SEE ALSO
ip(8), ss(8).
HISTORY
The ping command appeared in 4.3BSD.
The version described here is its descendant specific to Linux.
As of version s20150815, the ping6 binary doesn't exist anymore. It has
been merged into ping. Creating a symlink named ping6 pointing to ping
will result in the same functionality as before.
SECURITY
ping requires CAP_NET_RAW capability to be executed 1) if the program
is used for non-echo queries (See -N option), or 2) if kernel does not
support non-raw ICMP sockets, or 3) if the user is not allowed to
create an ICMP echo socket. The program may be used as set-uid root.
AVAILABILITY
ping is part of iputils package.
iputils 20211215 PING(8)
16. Comando Traceroute
El comando traceroute en Linux imprime la ruta que tarda un paquete en llegar al host. Este comando es útil cuando desea conocer la ruta y todos los saltos que toma un paquete.
La imagen de abajo muestra cómo se usa el comando traceroute para llegar al host de Google (142.251.133.4 esta IP no es la única de Google !) desde la máquina local y también imprime detalles sobre todos los saltos que visita en el medio.
17. Ejemplos uso Traceroute.
Opción tiempos q
Si queremos que solamente haga 2 ping por cada host intermedio, tendremos 2 tiempos y no tres.

Usamos el parámetro q:
Sets the number of probe packets per hop. The default is 3

Este último caso es 5, y se obtienen 5 tiempos.
Opción de NO fragmentar. -F

Traza desde un gateway. g

Opción ttl máximo m
-m max_ttl, --max-hops=max_ttl
Specifies the maximum number of hops (max time-to-live value)
traceroute will probe. The default is 30.

18. Manual de Traceroute
TRACEROUTE(1) Traceroute For Linux TRACEROUTE(1)
NAME
traceroute - print the route packets trace to network host
SYNOPSIS
traceroute [-46dFITUnreAV] [-f first_ttl] [-g gate,...]
[-i device] [-m max_ttl] [-p port] [-s src_addr]
[-q nqueries] [-N squeries] [-t tos]
[-l flow_label] [-w waittimes] [-z sendwait] [-UL] [-D]
[-P proto] [--sport=port] [-M method] [-O mod_options]
[--mtu] [--back]
host [packet_len]
traceroute6 [options]
tcptraceroute [options]
lft [options]
DESCRIPTION
traceroute tracks the route packets taken from an IP network on their
way to a given host. It utilizes the IP protocol's time to live (TTL)
field and attempts to elicit an ICMP TIME_EXCEEDED response from each
gateway along the path to the host.
traceroute6 is equivalent to traceroute -6
tcptraceroute is equivalent to traceroute -T
lft , the Layer Four Traceroute, performs a TCP traceroute, like
traceroute -T , but attempts to provide compatibility with the original
such implementation, also called "lft".
The only required parameter is the name or IP address of the destina‐
tion host . The optional packet_len`gth is the total size of the prob‐
ing packet (default 60 bytes for IPv4 and 80 for IPv6). The specified
size can be ignored in some situations or increased up to a minimal
value.
This program attempts to trace the route an IP packet would follow to
some internet host by launching probe packets with a small ttl (time to
live) then listening for an ICMP "time exceeded" reply from a gateway.
We start our probes with a ttl of one and increase by one until we get
an ICMP "port unreachable" (or TCP reset), which means we got to the
"host", or hit a max (which defaults to 30 hops). Three probes (by de‐
fault) are sent at each ttl setting and a line is printed showing the
ttl, address of the gateway and round trip time of each probe. The ad‐
dress can be followed by additional information when requested. If the
probe answers come from different gateways, the address of each re‐
sponding system will be printed. If there is no response within a cer‐
tain timeout, an "*" (asterisk) is printed for that probe.
After the trip time, some additional annotation can be printed: !H, !N,
or !P (host, network or protocol unreachable), !S (source route
failed), !F (fragmentation needed), !X (communication administratively
prohibited), !V (host precedence violation), !C (precedence cutoff in
effect), or !<num> (ICMP unreachable code <num>). If almost all the
probes result in some kind of unreachable, traceroute will give up and
exit.
We don't want the destination host to process the UDP probe packets, so
the destination port is set to an unlikely value (you can change it
with the -p flag). There is no such a problem for ICMP or TCP tracer‐
outing (for TCP we use half-open technique, which prevents our probes
to be seen by applications on the destination host).
In the modern network environment the traditional traceroute methods
can not be always applicable, because of widespread use of firewalls.
Such firewalls filter the "unlikely" UDP ports, or even ICMP echoes.
To solve this, some additional tracerouting methods are implemented
(including tcp), see LIST OF AVAILABLE METHODS below. Such methods try
to use particular protocol and source/destination port, in order to by‐
pass firewalls (to be seen by firewalls just as a start of allowed type
of a network session).
OPTIONS
--help Print help info and exit.
-4, -6 Explicitly force IPv4 or IPv6 tracerouting. By default, the pro‐
gram will try to resolve the name given, and choose the appro‐
priate protocol automatically. If resolving a host name returns
both IPv4 and IPv6 addresses, traceroute will use IPv4.
-I, --icmp
Use ICMP ECHO for probes
-T, --tcp
Use TCP SYN for probes
-d, --debug
Enable socket level debugging (when the Linux kernel supports
it)
-F, --dont-fragment
Do not fragment probe packets. (For IPv4 it also sets DF bit,
which tells intermediate routers not to fragment remotely as
well).
Varying the size of the probing packet by the packet_len command
line parameter, you can manually obtain information about the
MTU of individual network hops. The --mtu option (see below)
tries to do this automatically.
Note, that non-fragmented features (like -F or --mtu) work prop‐
erly since the Linux kernel 2.6.22 only. Before that version,
IPv6 was always fragmented, IPv4 could use the once the discov‐
ered final mtu only (from the route cache), which can be less
than the actual mtu of a device.
-f first_ttl, --first=first_ttl
Specifies with what TTL to start. Defaults to 1.
-g gateway, --gateway=gateway
Tells traceroute to add an IP source routing option to the out‐
going packet that tells the network to route the packet through
the specified gateway (most routers have disabled source routing
for security reasons). In general, several gateway's is allowed
(comma separated). For IPv6, the form of num,addr,addr... is
allowed, where num is a route header type (default is type 2).
Note the type 0 route header is now deprecated (rfc5095).
-i interface, --interface=interface
Specifies the interface through which traceroute should send
packets. By default, the interface is selected according to the
routing table.
-m max_ttl, --max-hops=max_ttl
Specifies the maximum number of hops (max time-to-live value)
traceroute will probe. The default is 30.
-N squeries, --sim-queries=squeries
Specifies the number of probe packets sent out simultaneously.
Sending several probes concurrently can speed up traceroute con‐
siderably. The default value is 16.
Note that some routers and hosts can use ICMP rate throttling.
In such a situation specifying too large number can lead to loss
of some responses.
-n Do not try to map IP addresses to host names when displaying
them.
-p port, --port=port
For UDP tracing, specifies the destination port base traceroute
will use (the destination port number will be incremented by
each probe).
For ICMP tracing, specifies the initial ICMP sequence value (in‐
cremented by each probe too).
For TCP and others specifies just the (constant) destination
port to connect. When using the tcptraceroute wrapper, -p speci‐
fies the source port.
-t tos, --tos=tos
For IPv4, set the Type of Service (TOS) and Precedence value.
Useful values are 16 (low delay) and 8 (high throughput). Note
that in order to use some TOS precedence values, you have to be
super user.
For IPv6, set the Traffic Control value.
-l flow_label, --flowlabel=flow_label
Use specified flow_label for IPv6 packets.
-w max[,here,near], --wait=max[,here,near]
Determines how long to wait for a response to a probe.
There are three (in general) float values separated by a comma
(or a slash). Max specifies the maximum time (in seconds, de‐
fault 5.0) to wait, in any case.
Traditional traceroute implementation always waited whole max
seconds for any probe. But if we already have some replies from
the same hop, or even from some next hop, we can use the round
trip time of such a reply as a hint to determine the actual rea‐
sonable amount of time to wait.
The optional here (default 3.0) specifies a factor to multiply
the round trip time of an already received response from the
same hop. The resulting value is used as a timeout for the
probe, instead of (but no more than) max. The optional near
(default 10.0) specifies a similar factor for a response from
some next hop. (The time of the first found result is used in
both cases).
First, we look for the same hop (of the probe which will be
printed first from now). If nothing found, then look for some
next hop. If nothing found, use max. If here and/or near have
zero values, the corresponding computation is skipped.
Here and near are always set to zero if only max is specified
(for compatibility with previous versions).
-q nqueries, --queries=nqueries
Sets the number of probe packets per hop. The default is 3.
-r Bypass the normal routing tables and send directly to a host on
an attached network. If the host is not on a directly-attached
network, an error is returned. This option can be used to ping
a local host through an interface that has no route through it.
-s source_addr, --source=source_addr
Chooses an alternative source address. Note that you must select
the address of one of the interfaces. By default, the address
of the outgoing interface is used.
-z sendwait, --sendwait=sendwait
Minimal time interval between probes (default 0). If the value
is more than 10, then it specifies a number in milliseconds,
else it is a number of seconds (float point values allowed too).
Useful when some routers use rate-limit for ICMP messages.
-e, --extensions
Show ICMP extensions (rfc4884). The general form is CLASS/TYPE:
followed by a hexadecimal dump. The MPLS (rfc4950) is shown
parsed, in a form: MPLS:L=label,E=exp_use,S=stack_bottom,T=TTL
(more objects separated by / ).
-A, --as-path-lookups
Perform AS path lookups in routing registries and print results
directly after the corresponding addresses.
-V, --version
Print the version and exit.
There are additional options intended for advanced usage (such as al‐
ternate trace methods etc.):
--sport=port
Chooses the source port to use. Implies -N 1 -w 5 . Normally
source ports (if applicable) are chosen by the system.
--fwmark=mark
Set the firewall mark for outgoing packets (since the Linux ker‐
nel 2.6.25).
-M method, --module=name
Use specified method for traceroute operations. Default tradi‐
tional udp method has name default, icmp (-I) and tcp (-T) have
names icmp and tcp respectively.
Method-specific options can be passed by -O . Most methods have
their simple shortcuts, (-I means -M icmp, etc).
-O option, --options=options
Specifies some method-specific option. Several options are sepa‐
rated by comma (or use several -O on cmdline). Each method may
have its own specific options, or many not have them at all. To
print information about available options, use -O help.
-U, --udp
Use UDP to particular destination port for tracerouting (instead
of increasing the port per each probe). Default port is 53
(dns).
-UL Use UDPLITE for tracerouting (default port is 53).
-D, --dccp
Use DCCP Requests for probes.
-P protocol, --protocol=protocol
Use raw packet of specified protocol for tracerouting. Default
protocol is 253 (rfc3692).
--mtu Discover MTU along the path being traced. Implies -F -N 1. New
mtu is printed once in a form of F=NUM at the first probe of a
hop which requires such mtu to be reached. (Actually, the corre‐
spond "frag needed" icmp message normally is sent by the previ‐
ous hop).
Note, that some routers might cache once the seen information on
a fragmentation. Thus you can receive the final mtu from a
closer hop. Try to specify an unusual tos by -t , this can help
for one attempt (then it can be cached there as well).
See -F option for more info.
--back Print the number of backward hops when it seems different with
the forward direction. This number is guessed in assumption that
remote hops send reply packets with initial ttl set to either
64, or 128 or 255 (which seems a common practice). It is printed
as a negate value in a form of '-NUM' .
LIST OF AVAILABLE METHODS
In general, a particular traceroute method may have to be chosen by
-M name, but most of the methods have their simple cmdline switches
(you can see them after the method name, if present).
default
The traditional, ancient method of tracerouting. Used by default.
Probe packets are udp datagrams with so-called "unlikely" destination
ports. The "unlikely" port of the first probe is 33434, then for each
next probe it is incremented by one. Since the ports are expected to be
unused, the destination host normally returns "icmp unreach port" as a
final response. (Nobody knows what happens when some application lis‐
tens for such ports, though).
This method is allowed for unprivileged users.
icmp -I
Most usual method for now, which uses icmp echo packets for probes.
If you can ping(8) the destination host, icmp tracerouting is applica‐
ble as well.
This method may be allowed for unprivileged users since the kernel 3.0
(IPv4, for IPv6 since 3.11), which supports new dgram icmp (or "ping")
sockets. To allow such sockets, sysadmin should provide
net/ipv4/ping_group_range sysctl range to match any group of the user.
Options:
raw Use only raw sockets (the traditional way).
This way is tried first by default (for compatibility reasons),
then new dgram icmp sockets as fallback.
dgram Use only dgram icmp sockets.
tcp -T
Well-known modern method, intended to bypass firewalls.
Uses the constant destination port (default is 80, http).
If some filters are present in the network path, then most probably any
"unlikely" udp ports (as for default method) or even icmp echoes (as
for icmp) are filtered, and whole tracerouting will just stop at such a
firewall. To bypass a network filter, we have to use only allowed pro‐
tocol/port combinations. If we trace for some, say, mailserver, then
more likely -T -p 25 can reach it, even when -I can not.
This method uses well-known "half-open technique", which prevents ap‐
plications on the destination host from seeing our probes at all. Nor‐
mally, a tcp syn is sent. For non-listened ports we receive tcp reset,
and all is done. For active listening ports we receive tcp syn+ack, but
answer by tcp reset (instead of expected tcp ack), this way the remote
tcp session is dropped even without the application ever taking notice.
There is a couple of options for tcp method:
syn,ack,fin,rst,psh,urg,ece,cwr
Sets specified tcp flags for probe packet, in any combination.
flags=num
Sets the flags field in the tcp header exactly to num.
ecn Send syn packet with tcp flags ECE and CWR (for Explicit Conges‐
tion Notification, rfc3168).
sack,timestamps,window_scaling
Use the corresponding tcp header option in the outgoing probe
packet.
sysctl Use current sysctl (/proc/sys/net/*) setting for the tcp header
options above and ecn. Always set by default, if nothing else
specified.
mss=num
Use value of num for maxseg tcp header option (when syn).
info Print tcp flags of final tcp replies when the target host is
reached. Allows to determine whether an application listens the
port and other useful things.
Default options is syn,sysctl.
tcpconn
An initial implementation of tcp method, simple using connect(2) call,
which does full tcp session opening. Not recommended for normal use,
because a destination application is always affected (and can be con‐
fused).
udp -U
Use udp datagram with constant destination port (default 53, dns).
Intended to bypass firewall as well.
Note, that unlike in tcp method, the correspond application on the des‐
tination host always receive our probes (with random data), and most
can easily be confused by them. Most cases it will not respond to our
packets though, so we will never see the final hop in the trace. (For‐
tunately, it seems that at least dns servers replies with something an‐
gry).
This method is allowed for unprivileged users.
udplite -UL
Use udplite datagram for probes (with constant destination port, de‐
fault 53).
This method is allowed for unprivileged users.
Options:
coverage=num
Set udplite send coverage to num.
dccp -D
Use DCCP Request packets for probes (rfc4340).
This method uses the same "half-open technique" as used for TCP. The
default destination port is 33434.
Options:
service=num
Set DCCP service code to num (default is 1885957735).
raw -P proto
Send raw packet of protocol proto.
No protocol-specific headers are used, just IP header only.
Implies -N 1 -w 5 .
Options:
protocol=proto
Use IP protocol proto (default 253).
NOTES
To speed up work, normally several probes are sent simultaneously. On
the other hand, it creates a "storm of packages", especially in the re‐
ply direction. Routers can throttle the rate of icmp responses, and
some of replies can be lost. To avoid this, decrease the number of si‐
multaneous probes, or even set it to 1 (like in initial traceroute im‐
plementation), i.e. -N 1
The final (target) host can drop some of the simultaneous probes, and
might even answer only the latest ones. It can lead to extra "looks
like expired" hops near the final hop. We use a smart algorithm to
auto-detect such a situation, but if it cannot help in your case, just
use -N 1 too.
For even greater stability you can slow down the program's work by -z
option, for example use -z 0.5 for half-second pause between probes.
To avoid an extra waiting, we use adaptive algorithm for timeouts (see
-w option for more info). It can lead to premature expiry (especially
when response times differ at times) and printing "*" instead of a
time. In such a case, switch this algorithm off, by specifying -w with
the desired timeout only (for example, -w 5).
If some hops report nothing for every method, the last chance to obtain
something is to use ping -R command (IPv4, and for nearest 8 hops
only).
SEE ALSO
ping(8), ping6(8), tcpdump(8), netstat(8)
Traceroute 11 October 2006 TRACEROUTE(1)
19. Resumen Capa 3